





-
开放科学(资源服务)标识码(OSID):

-
我国幅员辽阔,林果作物种类繁多,由国家统计局数据可知,目前我国林果种植面积超过1.280×107 hm2,年总产量高达2.961 1亿t[1]。然而,林果园的综合机械化率仅为25.88%,且智能化水平相对较低[2],在施肥、除草、施药、修剪及采收等生产环节中,对人工的依赖程度较高,导致作业效率低下、成本高昂,同时人工还面临受伤风险。以重庆青花椒园为例,人工采摘成本占鲜椒销售价格的30%~50%[3],且人工作业易被树皮刺伤。随着人口老龄化进程的加速以及劳动力成本的增加[4],提升林果园的农业机械化和智能化水平迫在眉睫。
自动导航技术是农业机械智能化发展的重要组成部分[5-6]。目前,田间导航的实现主要依赖于2种技术:卫星定位[7-8]和机器视觉[9-11]。相较于卫星定位,机器视觉导航因其成本低、复杂环境适应能力强且能够实现实时监控,故更适用于复杂场景的导航[12-13]。近年来,深度学习在机器视觉领域迅速发展,卷积神经网络在多种农业场景中的应用取得了较好的效果[14-16]。其中,基于深度学习的道路识别成为农机自动导航的关键环节,目前已有多位学者直接通过路面识别来提取行进道路[17-19]。李云伍等[20]针对复杂的山地丘陵环境,使用空洞卷积代替普通卷积,结合FCN网络的VGG-16模块,构建了田间道路场景的语义分割模型,经试验验证,PA和MIoU指标均优于FCN-8s。赵岩等[21]针对模型识别精准度不高的问题,使用U-Net网络与ResNet优势融合的方式,提出了UNet-ResNet34,成功应用于茶园垄间道路识别。然而,这些方法在树冠稀疏、邻行地面干扰的情况下效果不佳。为此,学者们开始探索利用树干辅助提取道路的方法。Zhang等[22]提出一种改进YOLOv5模型来检测果树树干、行人等物体,该模型将瓶颈网络替换为轻量级的GhostNet V2,并加入协调注意力机制(CA)以降低背景信息的干扰,试验结果表明,模型参数减少了46.9%,mAP达到了97.1%。Jiang等[23]使用R-CNN深度学习模型来检测树干进而实现不同光照条件下的道路提取,试验结果表明,模型的mAP为85.29%。彭书博等[24]以树干根部中点作为定位基点,利用改进YOLOv7模型得到两侧果树行线的定位参照点,并实现道路提取。
目前,针对丘陵山地复杂林果园场景的道路提取研究还相对较少,本文聚焦重庆丘陵山地典型林果作物——青花椒,开展青花椒园行间道路提取方法研究。首先,通过构建青花椒园行间数据集,利用BiSeNetv2网络模型对树干进行语义分割,并采用K-Means算法对左、右两侧树干特征点进行聚类;然后,引入改进的RANSAC方法,对聚类后树干特征点进行道路边界拟合,实现目标行间道路的重构;最后,通过树干分割和道路重构试验对本文提出算法的精度和有效性进行验证。
HTML
-
青花椒行间样本采集于重庆市江津区现代农业园区的宇隆椒丰农业开发有限公司花椒基地,采集时间为2023年7月至2024年7月,采集设备为佳能R100相机,采集时相机视角高度为0.5~1 m,采集的图像为1 280×720像素的RGB彩色图像。试验共采集了400张图片,其中包括训练集300张、验证集50张、测试集50张。图 1为采集到的部分典型青花椒园样本图像,采集场景包含不同光照条件、不同季节和不同地势3种情况。不同光照条件包括强光和弱光,强光照射导致树干上产生明显的阴影,同时由于镜面反射,叶片上会出现明亮的光斑,对场景识别造成干扰。不同季节包括夏季和冬季,2个季节中树形和道路情况差异较大,夏季树冠茂盛,枝干裸露少,道路杂草呈绿色;冬季树冠稀疏,枝干裸露多,道路多处被枯草覆盖。不同地势包括下坡和上坡,在下坡视角中,图像远景出现成片青花椒作物,对道路识别造成干扰。

-
在数据预处理时,考虑到语义分割算法对计算机内存资源的消耗,为提升训练速度,使用双线性插值方法将原始图像减少到512×512像素。使用Labelme软件手动对树干进行像素级注释,将青花椒树干标记为绿色(0,255,0),其余为背景并标记为黑色(0,0,0)。
-
语义分割旨在为图像中的每个像素赋予一个语义标签,以实现对图像中对象的精细和准确理解[25]。语义分割的核心是利用低层细节表示高层语义,往往需要较大的计算量,通常有2种方法来减少计算量:减小图像大小和降低模型的复杂度。减小图像大小可以最直接地减少计算量,但图像会丢失大量的细节,影响计算精度;降低模型的复杂度会削弱模型的特征提取能力,从而影响分割精度。现有的双边分割网络(Bilateral Segment Network,BiSeNet)能够很好地解决这个问题,将空间细节和分类语义分开处理,平衡了速度与精度要求。
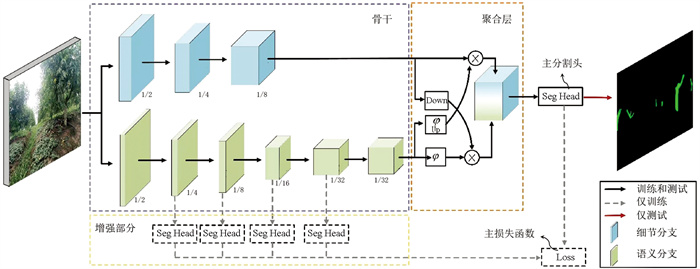
本文采用BiSeNetv2网络模型对树干进行语义分割,其模型框架如图 2所示,其核心由3大模块构成:紫色虚线框为双路径骨干(Backbone),橙色虚线框为聚合层(Aggregation Layer),黄色虚线框为增强部分(Booster)。模型具体结构为:①双路径骨干。主要由细节分支(Detail Branch)和语义分支(Semantic Branch)组成。细节分支凭借其较宽的通道数和较浅的层次结构,专注于捕获图像的低层细节,生成高分辨率的特征图,从而精确提取微观信息;语义分支则通过减少通道容量并采用高效的下采样策略,构建了一个轻量级的结构,深入探索高层上下文信息,有效提取宏观特征。②聚合层。提出了一种双向引导聚合层来融合连接细节分支和语义分支的输出特征。③增强部分。在训练时,分别在语义分支的1/4、1/8、1/16、和1/32下采样时增加辅助分割头和辅助损失函数。辅助分割头用于提供额外的监督信号,帮助梯度回流并加速训练,将浅层网络直接向后传递,从而引导中间层特征学习更好的语义信息;辅助损失函数监督语义分支的输出。最后,主分割头和主损失函数监控整个BiSeNetv2网络模型的输出。
-
本文的训练环境如下:操作系统为64位Windows 10系统,处理器采用13代英特尔酷睿处理器,GPU为RTX 4070 Ti。为了充分利用GPU的计算能力,使用NVIDIA提供的CUDA 11.1平台和cuDNN 8.0.4 GPU加速库进行训练。训练青花椒树干场景识别模型的超参数设置如下:初始学习率为0.005,预热迭代次数为50次,权重衰减为0.000 5,迭代次数为200次,训练和评估的批处理大小为4幅图像。
-
BiSeNetv2网络模型的主损失函数和辅助损失函数都选用交叉熵损失函数,并采用OHEM(Online Hard Example Mining)策略提高模型对困难样本的关注度,以改善模型在不平衡数据集上的表现。交叉熵损失函数如式(1)所示:
式中:y为真实标签;
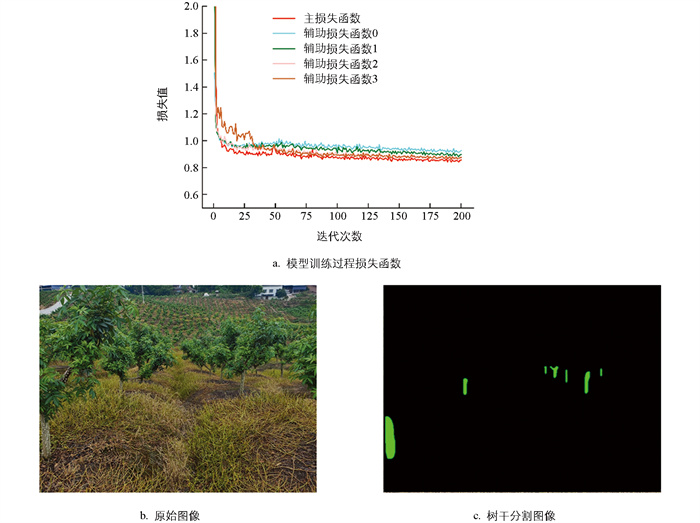
$\hat{y} $ 为模型预测的概率;E为样本总数;i为样本序号。模型训练过程中的损失函数曲线如图 3a所示,4个辅助损失函数和主损失函数都随着迭代次数的增加呈现协调下降的趋势,表明模型在各损失函数对应位置上的学习相互促进,提升了模型的整体性能。网络的主损失函数曲线在25次迭代前后稳定在0.85左右,收敛速度较快,同时损失函数整体曲线相对平滑,没有剧烈的波动,表明模型训练良好。训练完成后,模型分割青花椒树干的效果如图 3c所示。
1.1. 数据集采集
1.2. 数据集标注
1.3. 语义分割模型
1.4. 模型训练
1.4.1. 训练环境和超参数设置
1.4.2. 训练结果
-
根据相机透视原理,明显的道路在图像中应呈现“近宽远窄”的形态,道路边界在远端交会于一点,该点称为消失点[26]。丘陵山地青花椒园中的路面存在以下3种干扰,增加了道路识别的难度:①相邻行间路面噪声对目标行道路的识别产生影响;②地势起伏造成成像中的道路形态复杂,道路边界不明显;③园中路面情况复杂,包括被杂草、枯草、枝条及石块等物体覆盖,或道路上开设排水沟。考虑到青花椒园行间道路是由两侧成行种植的果树所形成的中间通道,因此识别两侧果树特征可替代道路边界特征,由于青花椒树冠形态随季节因素发生明显的改变,树冠并不适合作为固定生物特征来进行识别。因此,本文提出利用青花椒主干特征来重构道路。
-
青花椒树干基部与地面相接之处,可以视为界定道路边界的一个显著特征点。语义分割后,针对树干场景识别出的若干个连通区域,将每个区域中的最低点视为树干与地面的交点。遍历所有树干区域并标注最低点作为道路边界特征点。同时,考虑到语义分割模型树干场景的提取误差,设置面积阈值对较小面积的连通区域进行滤波。在图像坐标系下,特征点的选择参照式(2):
式中:St为第t个连通域像素点集,它包含了图像中连续分布的一组像素点;(ui,vi)为点集St中像素点的坐标;vmax为点集St中vi的最大值,即vmax是点集St中最低行像素点的v坐标值;uj为vmax对应的u坐标值。
考虑到最低行像素点可能存在多个,引入式(3):
式中:(uFP,vFP)为道路边界特征点坐标;uFP为所有最低行像素点的u坐标值的中值;N为最低行像素点的总数。
获得的道路特征点为道路左、右两侧的全部特征点,不能直接用于道路界线的拟合,需要对道路左、右两侧特征点予以区分。由于左、右特征点存在明显的横向间距,因此可以采用以欧几里得距离作为评价指标的K-Means聚类算法来实现道路两侧的分类。K-Means算法是一种无监督学习算法,广泛应用于各种分类任务,其算法目标是最小化簇内数据点与中心点之间的总距。设数据集为X={x1,x2,…,xn},C= { c1,c2,…,cK}为簇中心,则目标函数J如式(4)所示:
式中:K为聚类簇的数量;Si为第i个簇中的数据点集;‖xj-ci‖2为数据点xj到簇中心ci的欧氏距离。
使用欧几里得距离作为指标来度量数据对象之间的相似性,相似性越大,距离就越小,具体的算法流程为:
步骤1 随机选择K个数据点作为初始簇中心C,本文K取2。
步骤2 把每个数据点xj分配到最近的簇中心,得到Si,如式(5)所示:
步骤3 重新计算每个簇的簇中心ci,如式(6)所示:
步骤4 重复步骤2与步骤3,直到簇中心ci不再变化。
为提高算法运行速度,本文将最大迭代次数设置为30次。道路左、右边界特征点的提取流程如图 4所示。

-
青花椒园行间道路形态基本为直线,或在近视场内可近似看作直线,故道路边界重构简化为道路边界的直线拟合。语义分割模型的识别结果不仅包含目标行内的树干,还可能包括相邻行的树干,这些额外树干会对道路边界线拟合的准确性造成影响。本文提出采用对异常值不敏感的RANSAC算法来拟合边界线,同时基于道路边界的斜率特征改进投票机制以选择更优模型,从而提高边界线拟合的精确度和可靠性。
-
RANSAC算法是一种迭代方法,用于从1组包含噪声的观测数据中估计数学模型参数。在直线拟合中,RANSAC算法被用来从包含噪声的数据点中找到最佳的直线。这种方法尤其适用于数据集中存在错误测量或异常值的情况。RANSAC直线拟合算法流程为:
步骤1 初始化:给定数据集Y,其中包含N个数据点。选择最小的样本数(通常为2,2点确定1条直线),并随机从数据集Y中抽取这样的样本集合,记为Y1。
步骤2 模型生成:使用Y1中的样本点计算得到1个直线拟合模型M。
步骤3 数据分类:计算除Y1外数据集Y中所有点到直线模型M的距离。设置阈值T,当距离小于T时,则将该点判定为内点,否则判定为外点。将所有内点组成的新数据集记为Y*,它是Y1在当前模型下的一致性集合。
步骤4 模型评估与更新:比较当前模型M的内点数量与之前迭代中记录的最佳模型的内点数量,如果当前模型的内点数量更多,则更新最佳模型的参数以及最佳模型的内点数量。
步骤5 迭代:重复步骤1至步骤4,进行多次迭代。在每次迭代中,重新随机选择最小样本集Y1,并尝试拟合新的直线模型M,然后评估其一致性集合Y*的大小。
步骤6 结果输出:迭代结束后,输出最佳直线模型的参数以及对应的一致性集合Y*,该模型就是在给定数据集Y下,通过RANSAC算法找到的最佳直线拟合。
-
当图片中的树干总数较少时,噪声树干会对边界拟合产生严重影响,并使算法结果出现多个内点数一致的模型。针对以上问题,考虑到道路边界在透视变换下,其投影到笛卡尔坐标系时具有特定的斜率特征,本文提出了一种对RANSAC算法中模型评估环节的改进方法。具体而言,不再仅仅依赖于内点数量的简单对比来评估模型优劣,而是引入一种综合评分机制,该机制结合了内点数量与模型拟合出的边界斜率,共同对候选模型进行打分。通过这种方式,算法能够更准确地筛选出既符合数据点分布又贴近实际道路边界斜率特性的最佳模型,从而提高边界拟合的准确性和鲁棒性,具体的评分方法如式(7)、式(8)所示:
其中:SL、SR分别为左、右侧模型的得分;n为内点个数;p为模型M的斜率。
改进的RANSAC算法解释如下:对于左侧边界线拟合,算法会优先考虑斜率大于0的模型,并在这些模型中进一步选择斜率较大的值。因为在实际道路场景中,噪声树干通常出现在左侧目标行的左上方,左侧边界线通常呈现为正斜率且斜率大于加入噪声点模型的斜率。相反,在拟合右侧边界线时,算法则偏好选择斜率小于0且绝对值较大的模型,以符合右侧边界线负斜率的特征。
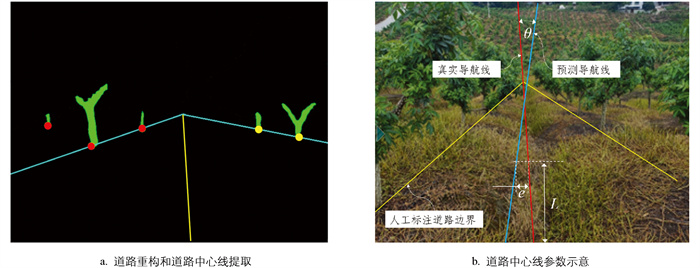
本文内、外点的判断阈值T取50像素,为了保障运行速度,最大迭代次数设为30次,每次拟合的最小样本数量为2。道路边界线拟合结果如图 5a中的蓝色线条所示,边界线之间的区域视为重构的道路。为分析道路重构的效果,引入道路中心线的航向偏差θ和横向偏差e作为道路重构精度的衡量指标。道路中心线为边界线的角平分线,θ为真实道路中心线与重构道路中心线的夹角,e为距图像底端L像素水平位置的真实道路中心线与重构道路中心线的横向偏差距离,其中真实道路中心线为人工手动标注道路边界线的角平分线,如图 5b中的红色线段所示。
2.1. 道路边界特征提取与K-Means道路两侧分类
2.2. 改进RANSAC算法的道路边界线拟合与道路重构
2.2.1. RANSAC算法
2.2.2. 改进RANSAC算法
-
在语义分割任务中,一般需要对模型进行准确性和实时性的评估。语义分割的精度直接影响道路重构的质量,本文采用平均交并比(MIoU)和平均像素准确率(MPA)评估模型精度。平均交并比计算每个类别的交并比(IoU),然后对所有类别取平均,能够提供全面的性能评估,如式(9)所示。平均像素准确率则是对每个类别的像素准确率进行平均,旨在衡量模型对每个类别的预测性能,能够反映模型在各个类别上的表现,如式(10)所示。
其中:MIoU为平均交并比;AMP为平均像素准确率;k为除背景之外的语义分割类别的数量;Pii为属于第i类并被预测为第i类的像素点总数;Pij为属于第i类但被预测为第j类的像素点总数。
本文用参数量以及模型推理速度来评估模型的实时性。模型参数量是模型在运行时使用的计算机内存资源的实际数量,参数量的大小反映了模型的复杂度和学习能力。推理速度通常定义为模型在一次推理过程中所需的时间,可以表征模型的实时水平。
-
为了系统评估BiSeNetv2网络模型在语义分割任务中的性能表现,本文在统一的数据集划分(即相同的训练集与测试集)以及一致的训练环境设置下,对3种经典的语义分割模型(UNet、DeepLabv3+和本文所采用的BiSeNetv2模型)进行性能对比分析,3种模型的评估结果如表 1所示。由表 1可知,所有模型均展现出较高的分割准确性,平均维持在92%左右,表明模型训练效果良好,但它们在运行效率方面呈现出显著差异。具体而言,相较于UNet模型,BiSeNetv2在平均交并比与整体准确性上略有下降,分别低了1.01和0.13个百分点,平均像素准确率提升了2.79个百分点,显示出在细粒度分割任务上的优势。同时其推理速度约为UNet的8倍,模型参数量约为UNet的1/5,显著降低了计算资源需求,提高了实际应用中的部署效率。与DeepLabv3+模型相比,BiSeNetv2在平均交并比、平均像素准确率以及整体准确性上均有所提升,分别高出1.22、3.45、0.14个百分点。尽管两者在参数量上相近,但BiSeNetv2的推理速度约为DeepLabv3+的1.6倍。综合来说,BiSeNetv2网络模型兼顾准确性和实时性,其综合性能在三者中最为优异。图 6为3种网络模型的语义分割结果对比图。

-
采用道路中心线的航向偏差θ和横向偏差e作为道路重构精度的衡量指标,同时计算道路重构准确率。参照相关研究内容,本文将道路准确重构定义为:道路中心线的航向偏差θ≤10°,横向偏差e≤50像素。为了评价本文道路重构算法对青花椒园道路提取的效果,从训练集、验证集和测试集中随机抽取160张图片,用本文提出的算法(K-Means+改进RANSAC)与基于路面特征的道路识别算法[17-19]、基于树干特征的K-Means+最小二乘法道路重构算法、基于树干特征的K-Means+RANSAC道路重构算法进行比较分析。对4种道路提取方法进行量化统计,结果如表 2所示。
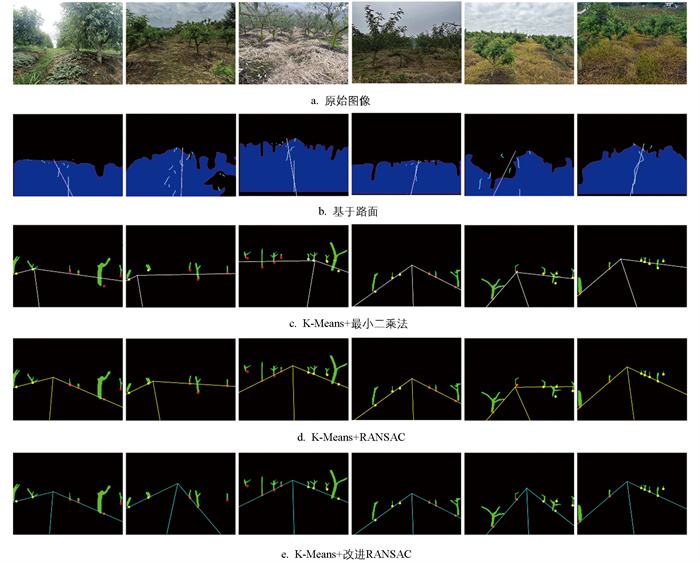
由表 2可知,基于路面的提取效果最不理想,道路中心线的平均航向偏差为17.25°,提取准确率为27.64%,其主要原因是青花椒种植环境复杂,造成提取的路面形状不规则,直接以提取的路面作为行间道路并不准确。基于K-Means+最小二乘法的道路中心线横向偏差的平均值和标准差分别为87.28像素和173.48像素,由于最小二乘法对邻行树干噪声的敏感性较高,该方法在重构道路时表现不佳。基于K-Means+RANSAC算法重构的道路中心线平均航向偏差为5.87°,平均横向偏差为36.28像素,准确率为75.36%,重构效果较好。本文方法(K-Means+改进RANSAC算法)的道路中心线平均航向偏差为4.28°,平均横向偏差为24.61像素,相较于K-Means+RANSAC算法的平均航向偏差和横向偏差分别减少了1.59°和11.67像素,算法准确率可达86.67%,较前3种方法分别提高了59.03、19.98、11.31个百分点,满足青花椒园内道路重构的准确性要求。
图 7为4种方法的道路提取结果对比,其中,本文基于K-Means+改进RANSAC算法的提取效果最优。该方法综合考虑了模型拟合的斜率和内点数量,能有效解决树干较少时RANSAC算法模型不稳定的问题,对算法进行斜率的偏好设置控制了算法对样本点的选择,使模型能将目标道路边界点准确且稳定地识别为内点,同时将邻行树干识别为外点,降低了由邻行树干导致的拟合误差,提高了道路重构的准确性。
3.1. 树干语义分割试验
3.1.1. 语义分割模型评价指标
3.1.2. 语义分割结果
3.2. 道路重构算法试验与分析
-
本文提出了一种基于树干特征的道路重构方法,采用BiSeNetv2网络模型对树干进行语义分割,将树干与地面的交点作为道路边界特征点,并通过K-Means聚类与改进的RANSAC算法相结合的方法实现道路边界拟合和道路重构,显著降低了邻行树干的干扰,提高了算法的稳健性。试验以青花椒园为对象,构建了400张青花椒园行间道路图像样本集,在UNet、DeepLabv3+和BiSeNetv2网络的语义分割结果对比评估中,BiSeNetv2网络模型的分割准确性为92.04%,推理速度为231 f/s,准确性和实时性较高,综合性能最好。本文的组合算法相较人工观测,其道路中心线平均航向偏差为4.28°,平均横向偏差为24.61像素,较RANSAC算法改进前提高了11.31个百分点,比传统基于路面的重构方法提高了59.03个百分点,能够满足青花椒园道路重构的需求,为林果园中农机视觉导航提供了技术参考。
 DownLoad:
DownLoad: