





-
在大数据时代,数据已成为一种新的战略资源,是推动创新的重要因素,并且正在改变各个领域研究的方式以及人们的生活方式和思维方式[1],许多国家相继发布了一系列大数据技术计划,大力推动了大数据的研究和应用[2-3]. 目前的研究一直致力于识别和分析每一个领域的巨大数据,大数据应用领域有医疗服务、银行业、市场营销等[4]. Cheng等[5]研究了大数据挖掘技术在智能生产中的应用.
大数据分类是识别输入大数据所属的类的过程,分类最流行的方法之一是通过使用给定的数据集训练机器学习算法来构造分类模型[6],Varatharajan等[7]提出支持向量机的心电图大数据分类方法,将支持向量机(Support Vector Machine,SVM)模型与加权核函数方法结合使用,从输入的心电图信号中分类更多特征. Lakshmanaprabu等[8]使用随机森林分类器,开发了基于物联网(IoT)的医疗系统大数据分析,使用改进的蜻蜓算法(Improved Dragonfly Algorithm,IDA)从数据库中选择最佳属性获得更好的分类. 张龙翔等[9]提出面向分布式数据流大数据分类的多变量决策树,设计了几何轮廓相似度的多变量决策树用于大数据分类. 但是上述方法都没有考虑到不平衡数据的处理问题,如果数据集不平衡,机器学习等分类算法不能够正确学习少数类数据,倾向于占数据集很大比例的大多数类,这可能会导致分类结果有偏差和决策错误[10].
为了减轻类不平衡问题,通常使用数据采样技术通过任一类中的数据数量来调整不平衡数据. 根据调整的类别,可以将它们分为欠采样技术和过采样技术[11]. 欠采样在多数类中删除数据,直到其数目等于少数类中的数据数为止,欠采样技术由于平衡数据删除而遭受信息丢失的问题. 过采样技术为少数类生成数据与多数类平衡,常用的过采样方法包括合成少数类过采样技术(Synthetic Minority Over-sampling Technique,SMOTE)、自适应合成采样(Adaptive Synthetic Sampling,ADASYN)和边界SMOTE[12]. 但是,过采样方法存在分类模型会被过度拟合到训练数据的问题. 另外,基于SMOTE的数据合成方法有时会产生多数类数据而不是少数类数据.
在研究现有大数据分类方法和采用方法的基础上,本文提出一种基于边界条件生成式对抗网络(Generative Adversarial Networks,GAN)的不平衡大数据分类方法,该方法利用条件GAN的类信息来产生少数类特征数据,然后在数据决策边界引入边界少数类到过样本,生成合适的少数类数据来提高分类性能. 基于相关因子和模糊理论,本文设计了相关模糊朴素贝叶斯分类方法对平衡大数据进行分类,并给出MapReduce框架下大数据分类的并行实现.
HTML
-
BCGAN利用决策边界条件GAN的类信息生成合适的少数类数据来提高分类性能. GAN由一个生成器和一个鉴别器组成. 条件GAN的结构和基本学习方法与GAN相似,区别是条件GAN的发生器和鉴别器考虑给定的条件.为了提高分类准确性,本文搜索位于决策边界附近的少数类数据,将其与其他少数类数据区分开. 使用borderline-SMOTE的边界样本选择方法找到边界少数类数据,步骤为:对于少数类中的每个数据实例,使用k最近邻(k-Nearest Neighbor,k-NN)算法计算其k个最近的数据实例,并得出其子集. 对于每个子集,如果属于多数类数据样本的数量大于或等于子集的大小,则将子集中的少数类数据视为边界少数类数据. 由于数据样本距离决策边界较远,因此将其保留在少数类别中. 最终,边界少数类包含原始少数类中靠近决策边界的数据.
BCGAN的目标是沿着多数类和少数类之间的决策边界生成少数类数据,需要对BCGAN进行训练. ①为给定的多数类和少数类计算边界少数类;②将类别信息以及来自高斯分布的随机选择的噪声输入发生器,生成器根据给定的输入数据生成伪造数据;③鉴别器试图通过使用类信息来区分真实数据和生成的数据. 根据条件GAN的损失函数,生成器和鉴别器会更新参数,并且通过重复此过程使损失最小化. BCGAN生成器可以生成反映边缘少数群体特征的数据.
训练完BCGAN之后,基于噪声和边界少数类数据,生成器可以产生与实际边界少数类数据相似的少数类数据,直到多数和少数类数据相同. 此时,这两个类具有相同的数据大小,即得出平衡的数据. 将生成的数据与现有的训练数据进行组合,然后将它们用于训练分类器.
-
现有的模糊朴素贝叶斯(Fuzzy Naive Bayes,FNB)分类器利用朴素贝叶斯(Naive Bayes,NB)和基于模糊的方法进行数据分类. 本文设计了相关模糊朴素贝叶斯(Correlative Fuzzy Naive Bayes,在CFNB)分类方法. CFNB分类器中,作为输入的训练数据需要表示为概率索引表,概率索引表表示数据样本作为数据矩阵,概率索引表的行和列表示数据和它们各自的属性. 本文所提出的CFNB分类器的训练样本表示为
其中T表示分类器的训练样本,Tp, q表示概率索引表第q属性中的p数据样本. d和a分别表示训练数据集中存在的总数据样本和属性. 式(2)给出向量形式的类.
其中G表示向量的类,gp表示p个数据样本的类. 数据样本中存在的属性对数据分类有更大的贡献. 考虑具有多个属性的训练数据样本. 因此,数据样本的属性表示为
其中H表示数据样本的属性,hq表示数据样本的第q个属性,在每个属性下分类的数据样本具有唯一的符号,CFNB分类器根据属性内的唯一数据符号计算模糊隶属度. 对于CFNB分类器隶属度的计算,考虑训练样本中唯一符号的第q个属性,S表示训练样本中的符号数量,符号的第q个属性由hq∈ms表示,s表示符号变量,取值范围为1 < s < S,CFNB分类器提供的训练样本第q个属性中s符号的隶属度可表示为uqs=|mqs|/d,其中|mqs|表示第q个属性中s符号的总出现次数,d表示属性中的数据样本数量. CFNB分类器将数据样本分类为K个类别,类总数的变化表示为Gk,其中k表示类别变量,取值范围为1 < k < K. CFNB分类器还为地面真相信息计算每个类的隶属度,带有基本事实信息第k类的隶属度可表示为uck=|mk|/d,其中c表示类别.
CFNB分类器与FNB不同之处:为训练数据集中存在的每个属性找到虚拟相关因子. 式(4)表示训练数据每个属性之间的虚拟相关性.
其中q表示属性变量,a表示训练数据集中存在的总属性数,Ck表示第k类中属性的虚拟相关性,f(·)表示相关函数. 通过将属性和训练样本的符号表示为对角矩阵来构造数据样本属性之间的相关函数. 式(5)表示训练数据属性之间的相关函数.
其中hq表示数据样本的第q个属性,hs表示数据样本的第s个属性,r(hs,hq)表示第s个和第q个属性之间的相关性. CFNB分类器考虑相关因子,找到训练数据中存在的数据样本之间的关系,并找到训练集中存在的独立数据样本的相关性. 查找属性中存在的唯一符号之间关系的相关因子表示为
其中函数correlativer(hs,hq)表示皮尔逊的相关系数,可以查找数据样本之间的线性相关性. 皮尔逊相关系数的一般表达式为
其中d表示属性中的数据样本数量,p为数据样本变量,取值范围为[1,d],tpq表示第q属性中存在的数据样本,tq表示第q属性中存在的数据样本的平均值,tps表示第q属性中的唯一数据符号,ts表示第q属性中唯一数据符号的平均值. CFNB分类器训练的最终输出包含来自属性的隶属度、来自地面真相信息的隶属度和相关因子. CFNB分类器的输出表示为
其中uqk表示第q个属性第k类的隶属度. 属性的隶属度具有(d×S)的大小,而地面真值信息的隶属度具有(1×K)的大小. 其中,d表示属性中的数据样本数量,S表示训练样本中的符号数量,K表示数据样本分类类别数量. 每个类表示属性唯一符号之间的相关系数具有(1×K)的大小,CFNB分类器的训练结果具有(d×S+2K)的总大小.
-
MapReduce框架由mapper和允许大型数据集同时运行的reducer组成,本文给出CFNB分类器训练和测试阶段的大数据分类过程. 在训练阶段,训练数据被输入到MapReduce框架,CFNB在训练阶段的MapReduce框架如图 1所示.
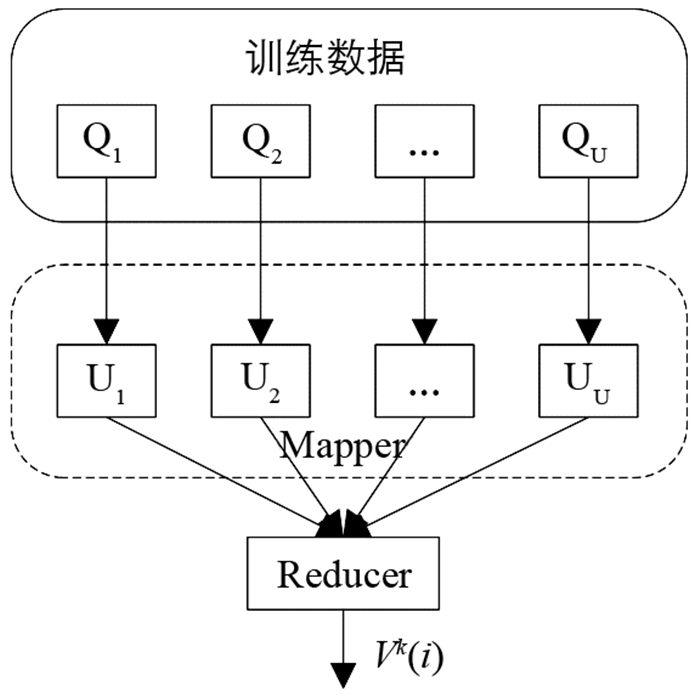
CFNB在测试阶段的MapReduce框架如图 2所示.
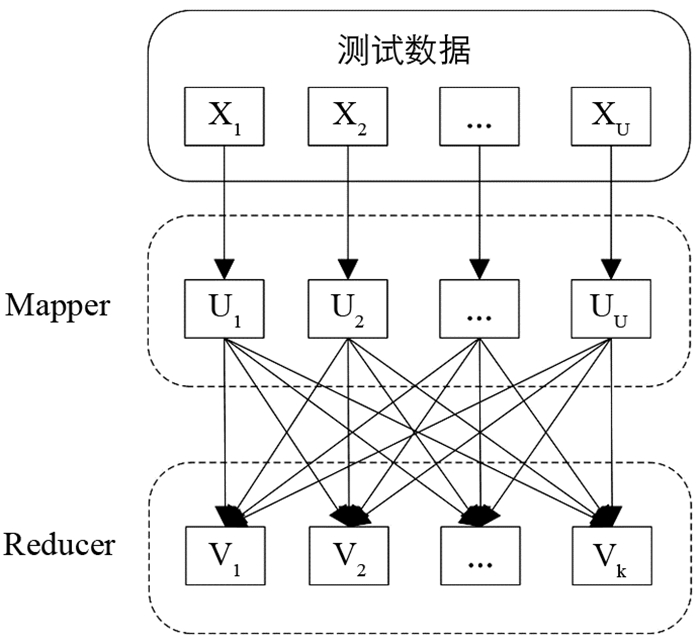
提供给mapper的测试数据表示为X,对测试数据X进行分区,测试数据包含U个部分数据样本和多个属性,计算每个映射器的隶属度、相关函数和mapper数据数量. 最后,mapper将信息提供给reducer合并信息,其中k小于U,并提供有关测试数据样本各部分类变量的信息,并最终分类.
2.1. 相关模糊朴素贝叶斯
2.2. CFNB的MapReduce并行实现
-
为验证本文所提算法的性能,将该算法和现有其他算法进行实验,所有实验在个人计算机中的Java平台上完成. 计算机配置如下:Windows 10操作系统、4 GB RAM和英特尔I7处理器. 实验大数据集是著名的PokHand数据集的不平衡版,由超过100万个具有10个预测属性的训练和测试样本组成.
对比算法有:文献[13]中基于混合采样策略的改进随机森林不平衡数据分类算法;文献[14]中基于鲸鱼优化+ SMOTE+双向递归神经网络的大数据分类算法;文献[15]中基于加权极限机器学习(WELM)和PSO的大数据分类算法. 表 1给出了不同算法的分类准确度对比结果.
从表 1可以看出,本文算法在不平衡大数据条件下分类准确度都高于其他3种方法,这是因为本文算法首先使用基于边界条件的GAN对不平衡数据进行处理,得到平衡数据,提高了分类准确度. 另外,使用虚拟相关因子的模糊NB对数据进行分类,进一步提高了分类准确率. 文献[14]中基于鲸鱼优化+ SMOTE+双向递归神经网络的大数据分类算法,分类准确度仅次于本文算法,这是因为使用鲸鱼优化+SMOTE对不平衡数据进行了处理,然后使用深度学习的双向递归神经网络提高了分类准确度. 文献[13]算法对不平衡大数据集表现出较好的分类结果,这是因为该算法使用混合采样方法对平衡数据进行了处理,为了验证本文算法的时间性能,得到平衡数据,提高了分类准确度.
针对加利福尼亚大学尔湾分校(UCI)机器存储库的定位数据集进行时间性能验证,该数据集包含人活动的信息. 且包含8个属性下164 860个样本实例. 大数据分类时间对比结果如图 3所示.
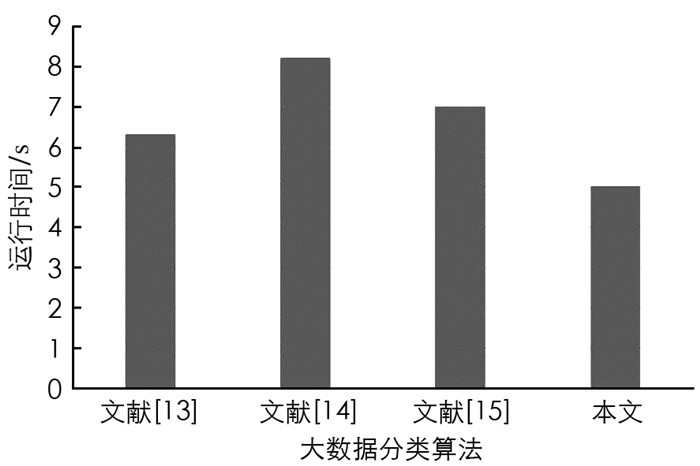
由图 3可以看出,本文算法的大数据分类时间最少,这是因为在MapReduce框架进行本文算法的并行化实现,大大减少了分类时间. 虽然文献[14]中方法分类准确度较高,但是递归神经网络耗时较大,导致分类时间最多.
-
本文提出一种基于BCGAN的不平衡大数据模糊分类算法,该算法使用BCGAN在多数类数据和少数类数据的决策边界附近引入一个边界少数类到过样本,生成更合适的少数类数据来提高分类性能,处理不平衡大数据,得到利于分类的平衡大数据,然后设计了基于相互因子和模糊理论的CFNB分类器. 将得到的平衡数据转换成概率索引表,通过相互因子和隶属度的引入进一步提高大数据分类性能,最后给出了MapReduce框架下的并行实现,降低了分类时间. 实验结果表明,与现有其他方法比较,针对不平衡率数据集,本文算法具有最优的分类准确度和最低的分类时间,说明该方法具有可行性和有效性.
 DownLoad:
DownLoad: