





-
开放科学(资源服务)标识码(OSID):

-
在农田CO2排放预测研究中,基于过程的生物地球化学模型,如农业技术转移决策支持系统(Decision Support System for Agrotechnology Transfer,DSSAT)、脱氮-分解模型(DeNitrification-DeComposition,DNDC)、环境政策综合气候模型(Environmental Policy Integrated Climate,EPIC)、农业生产系统模拟模型(Agricultural Production Systems sIMulator,APSIM),虽取得一定成效,但存在参数需求高、建模复杂、计算资源消耗大及环境适应性差等局限[1-2]。相比之下,机器学习方法因其强大的模式识别能力和良好的泛化性能,已成为农业碳排放预测的重要技术路径[3]。机器学习能从高频、长期的农田CO2排放浓度监测数据中挖掘复杂的非线性关联关系,并适应多变的环境和管理条件[4]。种植前,农户可通过预测模型评估碳排放量,调整施肥、灌溉量和耕作措施等。因此,建立基于机器学习的CO2排放浓度预测模型,不仅可弥补传统模型的不足,更可助力精准农业的发展与碳减排目标的实现,推动农业智能化、前瞻化管理迈向新阶段。
近年来,机器学习方法因其强大的非线性拟合与时序建模能力被应用于农田CO2排放浓度预测。文献[5]采用极限梯度提升算法(eXtreme Gradient Boosting,XGBoost)模型提升农田碳交换预测精度,弥补传统模型对非线性关系处理的不足。文献[6]将长短期记忆网络(long short term memory,LSTM)与XGBoost应用于CO2与CH4排放趋势预测,验证了二者在处理复杂时序数据中的有效性。文献[7]进一步探索了XGBoost、卷积神经网络(Convolutional Neural Network,CNN)与LSTM模型融合在碳排放预测中的潜力,取得了优异结果。文献[8]构建的CNN-GRU模型与文献[9]提出的CNN-LSTM模型,通过将擅长局部特征提取的卷积神经网络与擅长时序依赖建模的循环神经网络相结合,能够有效克服单一模型的局限性,在不同领域证实了混合深度学习架构的优越性。这一设计思路为本文解决农田CO2浓度多因子耦合时序预测问题提供了研究思路。总体来看,融合深度学习与树模型优势的组合模型成为主流趋势,尤其在非线性强、时序性显著的农业碳排放预测中表现出更高精度与稳定性。本文构建的基于LSTM时序特征拼接的XGBoost组合模型正是对该趋势的实践,可显著提升预测精度,为农田CO2排放浓度建模提供了新路径与理论支撑。
HTML
-
预测模型所用数据由基于STM32的农田CO2排放浓度测量全自动静态箱系统与基于Elasticsearch(ES)数据库的农田物联网云存储系统采集得到,两套系统于2024年8月和9月在苜蓿大田中部署,采样周期为苜蓿一茬完整生长周期。具体的数据采集现场示意图见图 1。基于STM32的农田CO2排放浓度测量全自动静态箱系统是一套基于32位微控制器(STM32)的全自动农田数据采集系统,箱体大小为75 cm×75 cm×75 cm,箱体底部配有插入土壤5 cm的密封水槽,系统可以全自动定时采集农田的CO2排放量(图 2)、环境温湿度和箱内温湿度数据;基于ES数据库构建的农田物联网云存储系统,通过部署光照强度、土壤温湿度、土壤电导率、风速传感器,土壤测量传感器均掩埋在地表 20~40 cm下,系统实时接收前端采集模块上传的农田环境数据,并利用ES实现数据的高效存储。

本研究所采集的数据包含CO2排放浓度、环境温湿度、光照强度、风速、土壤电导率及土壤温湿度。具体数据类型及变量说明见表 1。
-
本研究中两套采集系统经过时间戳对齐后的数据采集周期为20 min,每个周期间隔30 min,数据采集频率为3 s/次。采用均值降频法将采样频率从每3 s降频至1 min,降频后的部分数据如表 2所示,降频公式如下:
其中:xmean(t)表示降频后的1 min平均数据;N=20表示每分钟的采样点数;ti表示采样时间点,Δt=1 min。按1 min的时间窗口划分数据,在每个时间窗口内计算光照强度、土壤湿度、温湿度等变量的均值,将降频后的数据作为预测模型的输入。
-
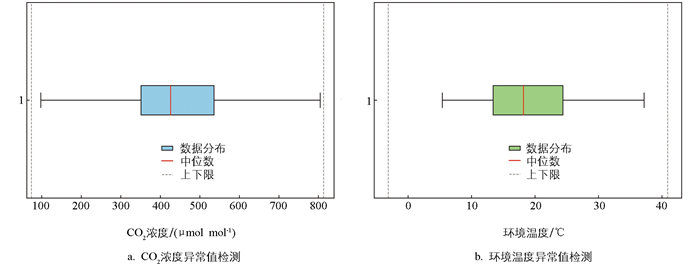
本研究采用3σ原则判定异常值,超出μ±3σ的值被视为异常并替换为相邻点的均值[10]。同时,根据实际场景设定环境变量合理范围,对于明显不符合实际的值进行清除。对于异常值的处理,采用邻点均值替换法:若异常点位于数据序列中间位置,则在其前后各取一个最近的正常数据点并计算均值以替换该异常值;若异常点位于序列首尾,则在单侧连续选取最近的2个正常点计算均值进行替换,保障替换值的合理性。本实验中,经均值替换与直接清除的异常值占总数据量的4.91%。对所有数据进行异常值处理,部分数据处理后的检测结果如图 3所示。
-
如(2)式所示,采用Min-Max归一化方法将所有特征值映射到[0, 1]区间以消除不同变量的量纲差异[11];如(3)式所示,对训练完整的预测数据进行反归一化操作,将数据还原到真实值[11]。
式中:$x^{\prime}$为归一化后的值;x代表原始特征值;xmin代表特征的最小值;xmax代表特征的最大值。
如(4)式所示,采用Z-Score方法对数据进行标准化处理;如式(5)式所示,对预测结果的数据进行反标准化处理。
式中:xstd表示标准化后的值;x表示原始特征值;μ表示特征的均值;σ表示特征的标准差。
-
本研究的数据经过降频处理后的数据量为3万条,将数据集按时间顺序划分为80%的训练集和20%的验证集,确保时间序列的完整性并模拟实际应用中的预测任务。为避免数据泄露问题并构建适合模型的样本,本研究采用了滑动窗口方法,该方法通过在时间序列上滑动一个固定的窗口,从序列中提取连续的子序列作为样本。每个样本的输入特征只包含当前时间步及其之前的信息,确保未来信息不会被泄露。
1.1. 数据来源
1.2. 数据预处理
1.2.1. 数据集降频
1.2.2. 异常值处理
1.2.3. 数据归一化与标准化
1.3. 数据集构建
-
为评估不同模型在农田CO2排放浓度预测中的表现,本文选取了LSTM、XGBoost、GRU和RF模型,并分别采用随机搜索与贝叶斯优化进行超参数调优[12-13]。输入变量包括农田CO2浓度、温湿度(环境、箱内、土壤)、土壤电导率、风速与光照。
LSTM与GRU模型用于建模时间序列特征,通过构建滞后变量增强其对时序依赖的学习能力,采用随机搜索在设定参数空间内进行优化,结合5折时间序列交叉验证,以均方根误差(Root Mean Square Error,RMSE)作为评估指标筛选最优超参数。
RF与XGBoost模型侧重于捕捉输入变量之间的非线性关系,采用贝叶斯优化策略提升搜索效率,同样以RMSE为核心指标,选择最优配置。最终,4种模型均在训练集上完成训练,并在验证集上评估性能,为后续混合建模提供基础支持。
-
本研究构建了多种基于LSTM和XGBoost的加权组合模型进行对比分析。加权组合模型是一种通过对多个基模型的预测结果进行加权平均,从而提升整体模型性能的方法。该方法尤其适用于单一模型性能无法达到理想水平,或者多个模型性能相似但在不同方面具有优势和劣势的情况[14]。本研究采用了基于决定系数(Coefficient of Determination,R2)的加权方式、基于RMSE倒数的加权方式、基于平均绝对误差(Mean Absolute Error,MAE)倒数的加权方式、基于R2、RMSE和MAE的平均加权方式以及网格搜索方法的加权组合方式,并从中筛选出最佳的加权组合方式。
基于R2值的加权方式以R2值作为评价标准,R2值越高,模型对数据的拟合效果越好,模型获得权重越大,计算公式为:
式中:s表示被评估基模型的R2值;si表示第i个参与组合的基模型对应的R2值;$\sum_{i} s_{i}$是所有参与加权组合的基模型R2值的和。通过这种方式,具有较高R2值的模型会在加权组合中占据更大的份额。
基于RMSE倒数的加权方式是为了衡量误差较小的模型,采用RMSE的倒数作为权重。对于误差指标,较小的值表示更优的模型,因此将获得更大的权重。基于RMSE倒数的加权计算公式为:
式中:eRMSE为被评估基模型的RMSE;eRMSE,i为第i个参与组合的基模型对应的RMSE;$\epsilon$为防止分母为零所引入的小常数,用于避免除零错误;$\sum_{i} \frac{1}{e_{R M S E, i}+\epsilon}$为所有基模型误差指标倒数的总和。误差越小的模型对应的倒数越大,权重也越大。
同理可得基于MAE倒数的加权计算公式为:
式中:eMAE为被评估基模型的MAE;eMAE,i为第i个参与组合的基模型对应的MAE。
计算出每个基模型在R2、RMSE和MAE上的权重后,按照(9)式求出平均权重,以此作为该基模型在最终加权组合模型中的权重。
通过这种方式,可以综合考虑加权组合模型在不同评估指标下的表现,从而进一步提升其性能。
除了使用R2加权、误差倒数法和平均加权计算权重外,本研究还通过网格搜索进一步优化加权组合模型的性能[15]。网格搜索的目的是通过对LSTM和XGBoost两个基模型的权重进行调优,找到最优的权重组合,从而提升加权组合模型的预测性能。在网格搜索中,两个基模型的权重在区间[0.1,0.9]上均匀取值,共有90个可能的权重组合,确保wlstm+wxgb=1。采用5折交叉验证,在每个权重组合下进行训练和验证,以减小过拟合风险,并确保加权组合模型在不同数据子集上的泛化能力。选择负均方误差作为评分标准,在网格搜索过程中,选择具有最小误差的权重组合作为最优解[16]。具体的加权组合计算公式为:
式中:ylstm和yxgb分别为LSTM和XGBoost基模型的预测结果;wlstm_opt和wxgboost_opt为通过网格搜索得到的最优权重。
-
混合预测模型是一种将多种不同的预测方法或算法结合起来使用的技术,可以提高预测的准确性、鲁棒性和泛化能力[17]。与单一模型相比,混合预测模型可以有效地克服单一方法存在的局限性,生成更加可靠和稳定的预测结果。
农田CO2排放浓度变化具有明显的时序特征和非线性特点。LSTM凭借其独特的门控机制,能够捕捉长期依赖与周期性模式[18]。XGBoost作为基于决策树的集成算法,擅长自动挖掘复杂的特征交互,能有效处理高维数据和非线性关系[19]。基于LSTM和XGBoost在各自领域的优势,本研究设计了如图 4所示的基于LSTM时序特征拼接的XGBoost组合模型(LSTM-XGBoost)。
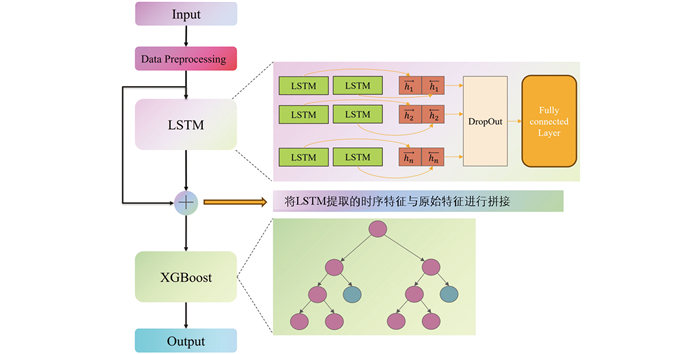
组合模型的输入数据包括CO2排放浓度、箱内温湿度、土壤温湿度、环境温湿度、土壤电导率、光照和风速。具体的构建步骤如下所示:
1) 使用LSTM模型对采集到的数据集进行训练,并使用随机搜索对LSTM进行超参数优化,以捕捉时间序列中的动态特征。LSTM会从数据集中提取各个数据项的时间特征,捕捉时间序列的周期性变化。时间序列数据如式(11)所示。
式中:$\boldsymbol{X}_{\text {orig }}$ 代表原始特征矩阵;n代表样本数;M代表每个样本的特征维度;$\boldsymbol{x}_{i}$代表第i个样本的原始特征向量。$\boldsymbol{X}_{\text {orig }}$通过LSTM网络处理后,会输出每个样本在连续时间步上的隐藏层状态序列,即LSTM提取的时序特征。第i个样本的时序特征序列定义如式(12)所示:
式中:$\boldsymbol{H}_{i}$代表LSTM提取的第i个样本的时序特征序列;T代表时间序列的步数;D代表LSTM隐藏层状态的维度;$\boldsymbol{h}_{i, t}$代表第i个样本在第t个时间步的隐藏层输出特征。
2) LSTM训练完成后,将每个样本对应的时序特征与原始特征进行水平拼接。由于XGBoost要求输入为一维特征向量,需先将二维的时序特征序列$\boldsymbol{H}_{i}$展平为一维向量,再拼接到对应原始特征向量$\boldsymbol{x}_{i}$的末尾。第i个样本的拼接特征向量定义如公式(13)所示:
式中:$\boldsymbol{X}_{\text {concat }, i}$ 代表第i个样本的拼接特征向量,由原始特征向量$\boldsymbol{x}_{i}$与展平后的LSTM时序特征序列拼接得到。将所有样本的拼接特征向量按行组合,即可得到最终输入XGBoost的训练特征矩阵,其定义如式(14)所示:
式中:$\boldsymbol{X}_{\text {train_concat }}$ 代表最终输入XGBoost的训练特征矩阵,维度为$n \times(M+T \times D), T \times D$ 代表单个样本的LSTM时序特征展平后的总维度。
3) 将特征矩阵$\boldsymbol{X}_{\text {train_concat }}$输入到XGBoost模型,并采用贝叶斯优化算法对XGBoost的超参数进行自适应调整。训练完成后,XGBoost将输出最终的CO2排放浓度预测值,其预测过程可表示为:
式中:K代表决策树数量,fk函数表示第K棵树对输入数据Xtrain_concat的预测结果。为评估模型的性能,采用时间序列交叉验证,确保模型在不同时间段的数据上进行验证,有效避免数据泄漏。同时使用负均方误差作为评估指标,衡量模型的预测精度和稳定性,从而确保组合模型能提供准确的CO2排放预测。
通过以上步骤的构建,LSTM可以捕捉数据集中时间序列的时间依赖性,将隐藏层特征与原始特征拼接后传递给XGBoost。XGBoost负责从特征中挖掘非线性关系进行预测。
2.1. 单一模型选取与优化
2.2. 加权组合模型的构建
2.3. 基于LSTM时序特征拼接的XGBoost组合模型设计
-
本研究采用MAE、RMSE、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)和R2作为评价指标。其中,RMSE表示模型预测值和真实值的平方误差的平均值的平方根,其计算公式如式(16)所示。MAE表示模型预测值和真实值的绝对误差的平均值,其计算公式如式(17)所示。MAPE用于评估模型的拟合效果,其计算公式如式(18)所示。R2的值通常介于0和1之间,越接近1则代表模型的拟合效果越好。R2可以用于评估模型的拟合能力,其中拟合效果好的模型的R2值较大,其计算公式如式(19)所示[20]。通过RMSE、MAE、MAPE和R2可以衡量模型的预测性能、分析模型的误差来源、预测的准确度以及拟合的质量。
式中:$y_{i}$代表真实值;$\hat{y}_{i}$代表预测值;$\bar{y}$代表真实值的平均值;n是样本数量。
-
GRU与LSTM在未优化前均使用默认参数进行训练。对GRU与LSTM使用随机搜索后的超参数搜索空间和最终的最佳参数组合如表 3所示。
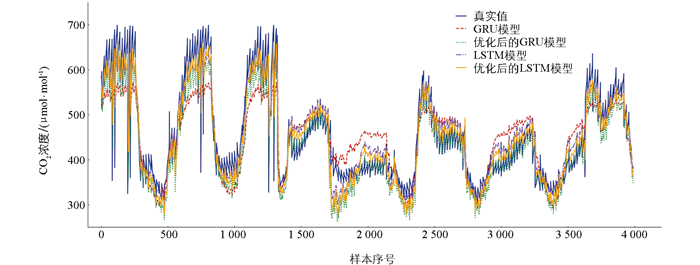
优化前后的GRU和LSTM预测趋势如图 5所示。从预测趋势分析来看,优化后的GRU和LSTM预测值比优化前更接近真实值。特别是在CO2排放浓度高值和低值区域,LSTM预测曲线与真实值更加接近。而优化前的GRU和LSTM在高CO2排放浓度时段存在一定程度的低估,在优化后得到了很大改善,但GRU的预测值比LSTM差。另外,在CO2排放浓度变化较为剧烈的时刻,优化后的LSTM具有更快的响应速度,滞后性有所改善。实验分析结果表明,LSTM具有更强的时间序列建模能力。
为了进一步分析GRU与LSTM模型的性能,计算出相关评价指标,结果如表 4所示。
从评价指标分析,优化后的LSTM和GRU相比优化前性能均有所提升。优化后的LSTM模型展现出更低的误差值和更高的拟合度,整体预测精度优于优化后的GRU模型。虽然GRU模型在优化后性能有所改善,但其RMSE和MAE明显高于LSTM,表明其预测误差较大。分析结果表明,在相同预测任务下,LSTM在各项指标上均优于GRU,LSTM具备更精准的预测能力、更强的建模能力以及更好的泛化性能。
综合上述误差分布与评价指标分析结果表明,在农田CO2排放浓度预测任务中,LSTM相较于GRU具有更显著的优势。LSTM在整体趋势跟踪上表现更为稳定,具备更好的长期预测能力。本研究最终选取LSTM作为组合模型的组成部分,以提升预测模型的整体性能。
-
RF与XGBoost在优化前均使用默认参数进行训练。RF与XGBoost模型的超参数搜索空间及最优参数结果如表 5所示。
RF和XGBoost预测趋势如图 6所示。从趋势图分析,优化前的RF和XGBoost均能较好地跟随CO2排放浓度的整体变化趋势,但XGBoost在拟合实际值方面表现更佳,能更准确地捕捉浓度波动的细节变化。RF模型在响应快速变化时表现较为迟缓,对CO2排放浓度波动的反应较为平缓,预测精度受限。优化后的XGBoost在农田CO2排放浓度预测中的表现明显优于优化后的RF。XGBoost不仅在整体趋势上保持良好拟合,而且在数据剧烈波动或复杂区域中依然能够保持较小的误差,预测结果稳定性与可靠性更高。虽然RF在优化后预测能力有所提升,但在高波动和快速变化的数据区间内仍存在较大的预测偏差,不能像XGBoost那样精确地跟随实际值的波动。
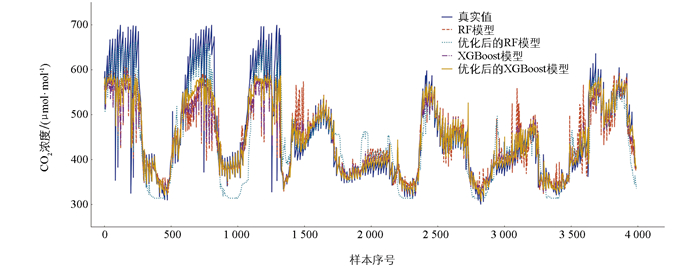
为了进一步分析RF与XGBoost模型的性能,计算出相关评价指标,结果如表 6所示。
性能分析结果表明,优化后的XGBoost和RF模型在各项指标上均优于优化前的表现。虽然RF优化后在一定程度上降低了RMSE,但其MAE和MAPE仍相对较高,说明其误差分布较大,预测稳定性仍不能达到预期要求。相比之下,XGBoost优化后的误差显著降低,并且拟合度提升,优化后的XGBoost整体预测精度优于RF优化模型。特别是在面对复杂的农田CO2排放数据时,XGBoost能够提供更低的误差和更高的预测准确性。
通过以上综合分析对比,在农田CO2排放预测方面XGBoost明显优于RF。XGBoost在局部波动区域的预测趋势和拟合能力优于RF,因此本研究选用XGBoost作为组合模型的一部分。
-
各加权组合模型的预测趋势如图 7所示。从图 7可知,不同的加权方法在CO2排放预测中均有较高的拟合度,但在CO2排放急剧变化时,所有加权方法的预测仍然存在偏差,误差幅度较小。最优加权组合模型和混合加权组合模型的预测值在大部分情况下能够较好地接近真实值,但在一些波动较大的区域仍存在一定误差。基于R2和MAE的加权预测模型的预测结果波动较大,不能始终跟随真实值。基于RMSE的加权预测模型的预测值在某些区域能够较好地反映真实值,在上述几种加权方式中预测性能最佳。
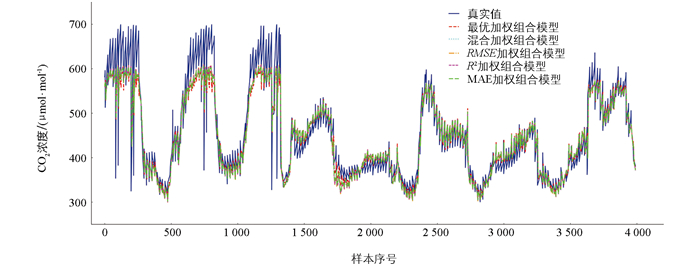
为了进一步分析不同加权组合模型的预测性能,我们计算了各项评价指标,结果如表 7所示。
从性能指标来看,加权组合模型的效果明显稳健。RMSE加权组合、MAE加权组合、R2加权组合等模型的RMSE和MAE普遍较低,表明加权组合模型具有更高的预测稳定性和准确性。在上述加权组合模型中,RMSE加权组合模型表现最优,各项性能指标均表现较好。通过以上综合分析结果,本研究选取了最优的RMSE加权组合模型与LSTM时序特征拼接的XGBoost组合模型进行最后的对比分析。
-
组合模型中LSTM与XGBoost的超参数优化后的最佳参数结果如表 8所示。
各模型预测趋势如图 8所示。LSTM-XGBoost组合模型结合了LSTM对时间序列特征的提取能力和XGBoost的非线性回归能力,使得预测曲线在短期和长期趋势上均能较好地拟合真实CO2排放浓度。相比其他单一和常规加权组合模型,LSTM-XGBoost组合模型在数据波动剧烈的区域预测误差更小,能够更精准地响应CO2排放浓度的突变趋势,组合模型能更好地适应CO2排放浓度的复杂变化,使得预测结果更加稳定。不同于单一模型和加权组合模型在短期剧烈波动和长期趋势变化时不能精准预测的不足,LSTM-XGBoost组合模型在不同时间段内提供更精准的CO2排放浓度预测。
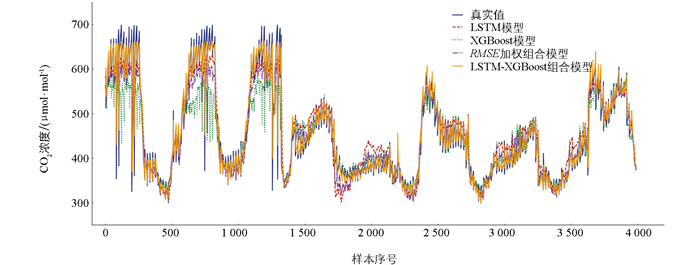
各模型误差趋势如图 9所示。LSTM-XGBoost组合模型的误差在大部分区间内保持最低水平并且波动较小,表明该模型能够更有效地结合LSTM的时序特征提取能力与XGBoost的非线性建模能力,在农田CO2排放浓度的预测任务中表现最佳。从综合分析结果来看,LSTM-XGBoost组合模型不仅降低了预测误差,还提高了预测的稳定性和可靠性,使其在CO2排放浓度预测任务中更具优势。
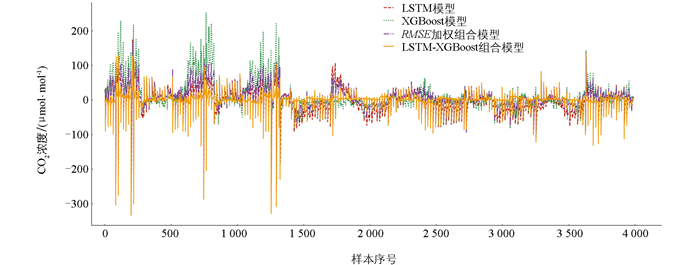
使用模型评价指标进一步分析各个模型的预测性能,各模型评价指标如表 9所示。
根据性能评价指标分析,LSTM-XGBoost组合模型在所有指标上均表现最佳,显著优于单独的LSTM和XGBoost模型以及LSTM和XGBoost的RMSE加权组合模型,展现出更高的预测精度和稳定性。LSTM-XGBoost组合模型在各项性能指标上均优于单一模型与加权组合模型。实验结果显示LSTM-XGBoost的RMSE降至22.81,MAE为9.97,R2提高至0.94,MAPE仅为2.21,显著优于其他模型,表明LSTM-XGBoost能够更精确地预测CO2排放的动态变化。
通过分析预测趋势、误差趋势以及多项评价指标,LSTM-XGBoost组合模型在农田CO2排放浓度的短期波动和长期趋势预测方面均表现优异,特别是在面对剧烈变化区域时依然能够迅速捕捉异常变化并做出响应。与单一模型和传统集成方法相比,组合模型在降低预测误差和增强泛化能力方面具有明显优势,为农田CO2排放浓度预测提供了一种更加高效和精准的解决方案。
3.1. 模型评价指标
3.2. GRU与LSTM模型对比分析
3.3. RF与XGBoost模型对比与分析
3.4. 基于LSTM与XGBoost的加权组合模型分析
3.5. LSTM时序特征拼接的XGBoost组合模型分析
-
针对农田CO2排放浓度预测中的建模问题,本文在对比现有单一模型性能的基础上,分析了基于LSTM时序特征拼接的XGBoost组合模型的有效性。文献[21]探讨了多种单个模型在农田CO2排放预测中的研究,研究表明LSTM在所有单个预测模型中的表现最佳(R2=0.87),稍高于本研究构建的LSTM预测模型(R2=0.86),但低于本研究提出的基于LSTM-XGBoost组合模型的R2=0.94。文献[22]使用模糊基函数回归(Fuzzy Basis Function Regression,FBFR)、支持向量回归(Support Vector Regression,SVR)、CNN及前馈神经网络(Feedforward Neural Network,FNN)对玉米农田CO2排放进行了预测,预测结果对比分析显示FNN的预测性能最佳,FNN预测性能的R2=0.918低于本研究提出的LSTM-XGBoost组合模型的R2=0.94,RMSE=67.75高于本研究LSTM-XGBoost组合模型的22.81。文献[23]利用反向传播神经网络(Back Propagation Neural Network,BP)对农田土壤CO2排放进行预测,预测性能的R2=0.918 8,低于本研究的LSTM-XGBoost组合模型。通过对比分析,本研究的LSTM-XGBoost组合模型预测精度高、误差小,为农田CO2排放浓度的预测提供了一种新的思路和方法。
-
本研究构建了LSTM、GRU、XGBoost和RF 4种单一机器学习模型,并分别对模型进行了随机搜索和贝叶斯优化。实验结果表明,LSTM在长期趋势捕捉方面优于GRU,XGBoost在短期非线性拟合方面优于RF。本研究通过实验验证了不同模型的差异化优势,同时也发现单一模型在面对农田CO2排放浓度数据中的复杂时序与非线性交互特征时,仍然存在一定的预测局限性。针对单一模型的局限性,本研究提出并建立了基于LSTM时序特征拼接的XGBoost混合预测模型,该模型充分融合了LSTM在长期趋势建模与XGBoost在短期非线性特征拟合方面的优势。实验证明该组合模型在预测精度和稳定性方面表现卓越,R2提高至0.94,RMSE降低至22.81,MAPE仅为2.21,相较于传统单一模型及常规加权融合模型有显著提高,为农田CO2排放浓度的精准预测提供了新的有效方法。
 DownLoad:
DownLoad: