


 下载:
下载:

-
面部表情识别可以反映人脸情绪, 现已经得到广泛研究[1].面部表情识别由以下部分组成:人脸检测(使用图像处理技术从整个图像中检测人脸)、特征提取(从检测到的脸部提取关键特征)和图像分类(使用机器学习模型对图像提取特征进行分类)[2].面部表情是视觉上可观察到的非语言交流信号, 是表达和理解情绪的关键机制.情绪识别领域的大部分研究都集中在对6种情绪(愤怒、恐惧、厌恶、喜悦、惊奇和悲伤)的分类上.
对于特征提取方法, 面部表情识别中广泛使用的特征描述技术有梯度方向直方图(histograms of oriented gradients, HOG)、韦伯局部描述等方法[3-4], 而梯度方向直方图已被证明在面部表情识别中效果显著.不过由于多视点特征的复杂性, 使得提取面部表情特征的维度通常很高, 因此诸如主成分分析、局部二元模式和非负矩阵分解等技术[5-6]正被用于解决特征高维问题, 在较低维度中表示最相关的特征来代替高维特征.
由于机器学习技术的特性, 使其更适应于非线性变换的自动特征学习和建模, 人们通过使用机器学习算法来进行各种面部特征分类, 如在文献[7]中提出了深度网络面部表情识别方法, 深度网络是基于两个不同的模型, 一种模型是从图像序列中提取时间外观特征, 而另一种模型是从时间面部界标点提取时间几何特征, 这两种模型结合使用一种新的集成方法, 以提高面部表情识别的性能.
文献[8]中提出了一种从面部显著区域提取融合特征的简化算法框架来实现面部表情识别, 该算法将梯度方向直方图与本地二进制模式相结合提取显著区域特征, 并使用主成分分析方法来减少提取的特征维数, 最后对减少的特征应用几个分类器, 获得较高的识别率.
自编码器模型已被广泛地用于分类和识别问题.文献[9]中提出一种面部表情识别的新框架, 以高精度自动区分表情.该方法将面部几何特征和外观特征组合而成的高维特征引入到面部表情识别中, 使用稀疏的自编码器网络进行特征学习和分类.该方法表情识别精度达到95.79%, 但是以计算复杂度为代价.
在研究了现有方法的基础上, 本文提出了一种深度堆叠自编码器的面部表情识别新方法.该方法利用自编码器网络特性, 在较低维度上有效地表示高维度面部特征, 同时能够检测到最相关的特征, 最终使用支持向量机(SVM)对特征进行分类, 大大提高了面部表情识别率.
全文HTML
-
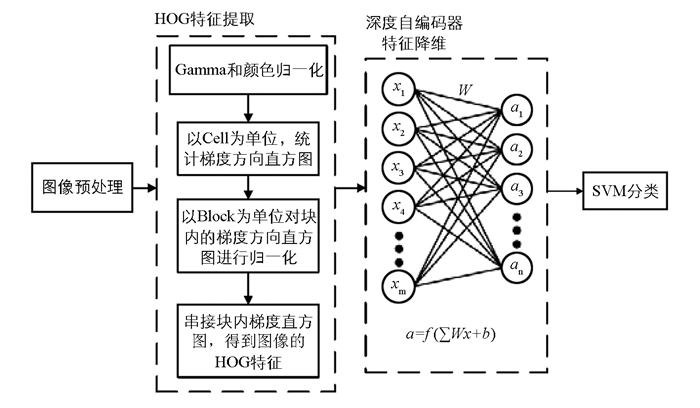
本文方法中面部表情识别通过人脸检测、特征提取、深度自编码器特征降维和SVM特征分类4个步骤实现.对于人脸检测算法, 本文采用的是Viola-Jones人脸检测算法, 检测并提取人脸区域, 消除影响识别率的冗余区域, 通过这种方式获得嘴巴和眼睛周围的脸部局部区域, 这些部位代表了最有鉴别力的信息.本文面部表情识别算法流程如图 1所示.
-
定向梯度直方图(HOG)是一种广泛用于计算机视觉和图像处理的特征描述方法, 除了对象的方向, HOG对于几何和光度转换是不变的.数据库中的图像具有不同表情和不同的眼睛、鼻子和嘴角的方向.本文表情识别方法将HOG应用于人脸图像特征向量提取, 128×128尺寸的裁剪图像使用HOG得出尺寸为1×8 100的特征向量, 特征向量连接起来形成特征矩阵.对于输入图像像素点(x, y)在水平方向梯度Gx(x, y)和垂直方向梯度Gy(x, y), 则有
其中, I(·)表示像素点的位置, 则像素点(x, y)的梯度幅值G(x, y)和梯度方向θ(x, y)可以表示为
然后, 使用高斯矩阵对梯度向量幅值做点乘, 对像素块边缘进行暗化, 建立梯度方向直方图, 对直方图归一化以后得到HOG特征描述值.
-
机器学习可以在较低维度上获得最相关特征的整体表示, 由于提取的HOG特征具有较高的特征尺寸, 通过使用不同的降维技术(如主成分分析法PCA、线性判别分析法LDA和非负矩阵分解法NMF)来降低特征向量的维数.本文采用深度自编码器进行特征降维.
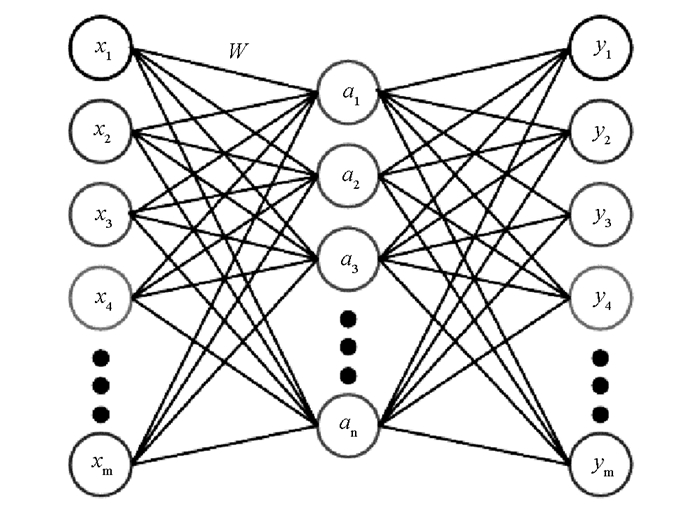
自编码器是一种无监督的体系结构, 在其输出处复制给定的输入, 其采用输入特征向量X, 并通过将原始输入数据从一个表示改变到另一个表示来学习代码字典.自编码器通过将目标值设置为输入来应用反向传播, 自编码器的结构如图 2所示.
长度为m的输入向量X被编码为长度为n的低维特征向量a, 其中n < m, 然后被重构成长度为m相似于x的向量y.如果自编码器输入相关的结构数据, 则网络将发现这些相关性, 在自编码器中较低维度向量a表示为
其中, W是与输入单元和隐藏单元相关联的权向量, b是与隐藏单元相关的偏置向量, a是网络中隐藏层的输入, f(∑ Wx + b)表示非线性输入映射函数, 本文采用sigmoid函数作为映射函数, 表示为
其中, Wi是第i个输入单元和隐藏单元相关联的权值向量, bi是与隐藏单元相关的偏置向量, 低维特征向量可以表示为ai=f(zi), 具体表达式见式(8), 即为深度自编码器数学描述.
即使当隐藏单元数量很大时, 自编码器也可以通过对隐藏单元施加稀疏约束来发现数据的相关结构, 这种架构被称为稀疏自编码器.稀疏自编码器的代价函数J(W, b)为
其中, 式(9)中第一部分公式尽量减小输入与输出的差异, 第二部分是避免过度拟合的权重衰减, hW, b(x)是激活函数, W和b分别表示权重矩阵和偏置矩阵, λ是权重衰减参数, L是自编码器网络层数, sl表示第lth层的单元数, Wji(l)表示层l第i个单元和层l+1第j个单元间的权重值, bi(l)表示层中l+1第i个单元的偏置量,
$\beta \sum\limits_{j = 1}^{{s_2}} {KL\left( {\rho \left\| {{{\hat \rho }_j}} \right.} \right)} $ 表示稀疏惩罚项, β为惩罚系数, ρ是稀疏参数, KL表示Kullback-Leibler (KL)散度, 其表达式为式中ρ被设置为接近于0的值. KL散度是用于测量两个不同分布之间差异的标准函数.
本文中使用HOG提取的特征输入到自编码器网络, 通过限制隐藏层中的隐藏单元将其编码在较低维度上.另外, 通过实验来验证增加深度自编码器隐藏层数与表情识别率的关系, 为了保证自编码器获得编码特征的质量, 本文使用反向传播来微调网络参数, 并使用均方误差(MSE)作为损失函数.
-
支持向量机是二元和多类分类问题的强大工具, 最初SVM被设计用于二进制分类, 以最大化的余量分离二进制类数据, 但是对于现实世界的问题, 通常需要区分两个以上类别的数据.因此, 两个有代表性的方案存在于支持向量机中, 即一对一和一对多类数据进行分类.本文使用具有高斯核的SVM一对多分类方法.
在一对多方案中, SVM构造k个独立二元分类器对k类数据进行分类, 第m个二元分类器通过使用第m类的数据作为正训练样本, 其余k-1个数据为负训练样本.在实验过程中, 类标签由二元分类器进行预测, 从而给出最大输出值, 对于训练数据xi(i=1, 2, …, N)和对应标签yi=±1的二元分类任务, 可以将判定函数表示为
其中, wT+b=0表示分离超平面, w是与分离超平面垂直的权向量, 并且b表示超平面的偏置向量, 以下是超平面之间的区域, 也称为边缘带.
最后, 选择w和b的最优值作为优化问题.其中, 式(12)受到以下约束最大化为
其中, xi为训练数据, yi为对应标签, w是与分离超平面垂直的权向量, b表示超平面的偏置向量.
1.1. HOG特征提取
1.2. 深度自编码器特征降维
1.3. 支持向量机面部表情分类
-
使用CK+数据库数据来对本文面部表情识别方法进行评估.该数据集包含来自123个主题的593个图像序列, 其中327个被赋予7个人脸表情的标签, 本文用了6个表达式(即愤怒、厌恶、恐惧、快乐、悲伤和惊奇), 每个表达图像序列以中性表达开始, 并以峰值表达(即愤怒)结束.在本文实验中, 使用每个表达式的5个峰值图像来合并表达式的时间信息.
图 3显示了用于训练的6种情绪的图像序列.本文使用80%的数据进行训练, 而使用剩下20%数据进行测试.在实验过程中, 只使用每个表达式的一个峰值图像.
本次实验对本文深度自编码器和PCA获得不同长度的特征进行了对比实验, 如表 1中所示.
由表 1中数据可知, 堆叠自编码器获得的编码特征优于PCA性能, 采用自编码器进行降维处理, 在60维的情况下识别率达到了99.60%, PCA的识别率在维度为80维时达到了96.44%.
另外, 本文还对自编码器网络中增加隐藏层与识别效果的关系做了实验, 引入更多具有不同数量的隐藏层(即500, 400, 300, 200), 编码特征数量范围为5~100.本文使用5个自编码器进行实验, 对自编码器网络中隐含层数的数量与识别效果的关系进行研究(表 2).
表 2显示了引入不同数量隐藏层的实验结果.由此可知隐藏层数量越多, 不一定会提高精度.在每个特征数的隐层数达到一定数量后精度开始下降, 例如当特征维度为80时, 隐藏层增加到第二层的时候识别率最高.
另外, 将本文方法和新的一些面部表情方法进行对比实验, 具体对比结果见表 3.
从表 3中数据可以知, 使用文献[12]中方法得到的最大识别准确率是99.51%, 本文方法得到99.60%的识别精度, 高于现有的识别方法.
虽然本文提出的方法已经达到了较好的识别率, 但是自编码器的时间复杂度线性地依赖于特征和隐藏层的数量, 特征或隐藏层数量越多, 训练模型所需的时间就越多.未来的工作将要考虑如何减少训练模型需要的时间, 提高表情识别效率.
-
本文提出了一种深度自编码器的面部表情识别新方法, 该方法使用HOG方法提取面部特征, 利用深度自编码器特性, 将高维度面部特征在较低维度上表示, 使用SVM进行分类, 实现面部表情识别, 具有降低特征维度的性能.在CK+数据集上的实验结果表明, 使用自编码器的非线性降维比PCA的线性降维性能更有效; 对自编码器网络中隐含层数数量与识别效果的关系进行研究, 增加了网络的学习能力, 为面部表情识别提供了更好的理论支撑.与现有表情识别方法相比, 本文方法具有更好的识别准确度, 高达99.60%, 证明了本文方法的有效性.