


 下载:
下载:
-
新零售是通过运用互联网新技术与新思维, 以消费者体验为核心的数据驱动零售模式.在移动互联网时代, 消费主体产生的数据规模呈爆炸式增长, 为精准挖掘用户需求和行为预测创造了客观条件[1].
以优惠券盘活老用户或者吸引新客户进店消费, 是新零售推动线上与线下业务跨界融合的重要方式[2], 然而优惠券的随机投放可能会对用户造成一定程度的干扰.对商家来说, 优惠券的滥发也可能会降低品牌声誉, 同时显性增加营销成本[3].所以, 个性化投放是提高新零售优惠券核销率的重要技术, 需要针对用户的消费偏好进行预测, 直接的预测目标是用户在领取优惠券之后的一定期限内是否会进行消费.所以, 优惠券使用预测是一个典型的二分类问题.
XGBoost[4]是近年来诞生的基于梯度提升决策树的集成学习算法, 在系统优化和机器学习原理方面都进行了深入的拓展. XGBoost因其可并行化的特点、优良的学习效果以及高效的训练速度而获得了广泛关注.
现有的优惠券投放相关研究主要以Im等[5]基于TAM和IDT(创新扩散理论)的理论为基础, 探究优惠券使用意图的影响因素.汪明远等[6]通过使用Smart PLS建立了结构方程模型, 并对问卷调查数据进行了分析, 发现使用态度和从众行为均能提高消费者移动优惠券的使用意愿.但以上研究均未利用消费者使用优惠券的真实数据.王小平等[7]发现Boosting类算法能显著提高分类模型的训练速度.任浩等[8]将XGBoost应用于文本情感识别, 取得了较高的分类准确度.王重仁等[9]将XGBoost算法引入了互联网用户的行为预测, 表明XGBoost对用户行为预测有理想的效果.
本文使用真实的消费者线上线下交易数据, 并将XGBoost引入到优惠券使用预测中.通过挖掘用户的行为信息, 建立分类预测模型, 从而精准预测用户是否会在期限内使用相应的优惠券.结果表明, 在预测优惠券使用的问题上, 与传统的机器学习算法相比, XGBoost具有准确度高、速度快等优势.
全文HTML
-
本文所使用的数据来源于口碑网在2016年1月1日-2016年6月30日之间的真实线上线下消费行为, 目的是预测用户在2016年6月领取优惠券后是否会在7月1日前核销.消费券核销的度量方法是:如果Date=null&Coupon_id!=null, 表示领取优惠券但未使用; 如果Date!=null&Coupon_id=null, 则表示普通消费; 如果Date!=null&Coupon_id!=null, 则表示优惠券已核销.
数据集共有477 355条记录, 字段描述如表 1.
-
缺失值的存在一般会严重影响模型质量和预测精度.首先进行缺失值填充, 将缺失值统一转化为NULL(空)类型.
消费行为具有很强的时间相关性, 在节假日前后会出现较大波动.数据集中的日期记录为字符串格式, 需要进行日期离散化.将日期转换为星期几、是否节假日、是否节前、是否节后等离散变量的形式.
将距离转换成[0, 10]之间的数字. x in(0, 10)表示距离为500×x米, 0表示低于500米, 10表示大于5 km.
数据集中的折扣形式有2种: x\in[0, 1]代表折扣率; x: y表示满x减y.需要将2种方式进行统一.将满减转换成折扣率的形式更好操作, 得到discount_rate, discount_man和discount_jian这3个变量.
-
在过去的研究中, 学者主要根据个体动机来研究优惠券的使用行为.巫红霞[10]解构了电商消费者购买的行为模式. Im等[5]基于TAM和IDT的理论研究, 发现优惠券使用意图主要受消费者对商家的态度和个人信息披露影响.龚艳萍等[11]所验证的影响因素包括优惠券属性、消费者属性、产品属性.结合以往的研究与数据集特点, 本研究划分了4个特征集(表 2).
1.1. 数据预处理
1.2. 特征选择
-
从数学模型角度上来说, XGBoost本质上是一个加强版的梯度提升树, 可以用来做回归和分类.和以往梯度提升树(gradient boosted tree, GBT)相比, XGBoost的优势在于提高了泛化度(正则项、缩减率、列抽样), 提高了精确度(二阶导), 提高了速度(算法优化、系统优化).
1) 目标函数定义:其中i表示第i个样本, l((
${\hat y_i} $ , yi))表示第i个样本的预测误差,$\sum\limits_k {\Omega \left( {{f_k}} \right)} $ 表示树的复杂度, T表示叶节点的个数, w表示叶节点的数值.2) 目标函数采用加法训练, 不是直接优化整个目标函数, 而是分步骤优化目标函数, 首先优化第一棵树, 之后优化第二课, 直至优化完成第K棵树.
3) 在第t步时, 我们添加了一棵最优的CART树(分类回归树)ft, 这棵最优的CART树就是在现有t-1棵树的基础上, 使得目标函数最小的那棵CART树.
4) 对目标函数进行二阶泰勒展开.
5) 将J看作f的函数, 因此l((yi,
${{\hat y}_i}^{\left( {t - 1} \right)} $ )可以看作常数项拿掉.6) 定义分裂的候选集合Ij={i|q(xi)=j}为叶子j的集合, 化简上式得
7) 定义
$ {G_j} = \mathop \sum \limits_{i \in {I_j}} {g_i}, {H_j} = \mathop \sum \limits_{i \in {I_j}} {h_i}$ , 并对wj求导, 得到目标函数最优解和最优权重. -
分类准确率(Accuracy)是指所有正确的分类占全部标签的百分比.分类准确率这一衡量分类器的标准比较容易理解, 但是该标准不能反应出响应值的潜在分布, 也不能输出分类器犯错的类型.所以, 本文主要以AUC作为主要评判标准.
AUC(Area under curve)是用于二分类模型的评价指标. AUC表示随机选择一个正样本和一个负样本, 分类器能够正确地给出正样本的score高于负样本的概率.假设M为正样本的数量, N为负样本的数量.首先对score进行排序, 之后令最大score对应的sample的rank为n, 次大的score对应sample的rank为n-1, 以此类推.然后把所有正样本的rank相加, 再减去2个正样本相组合的情况, 得到的结果表示所有样本中有多少对正样本的score大于负样本的score, 然后再除以M×N, 即:
-
类别数据分布不均衡是分类任务中一个常见的问题, 所以在分类模型构建之前, 需要对分类不均衡性的问题进行处理.本数据集中标签为0的样本数远大于标签为1的样本数.
本文采用K折交叉验证法来解决这一问题[12]. K折交叉验证实质上是将实验重复地进行K次, 首先将原始数据随机分成K个数据集, 每次实验都从这K个数据集中选择一个不同的集合作为测试集, 剩余的K-1个作为训练集进行实验, 最后将得到的K个实验结果取平均值.
K折交叉验证能够避免欠拟合和过拟合, 更好地说明模型结果.在XGBoost库中, 通过xgb.cv函数进行交叉验证.
2.1. XGBoost算法
2.2. 评价标准
2.3. K折交叉验证法(K-CV)
-
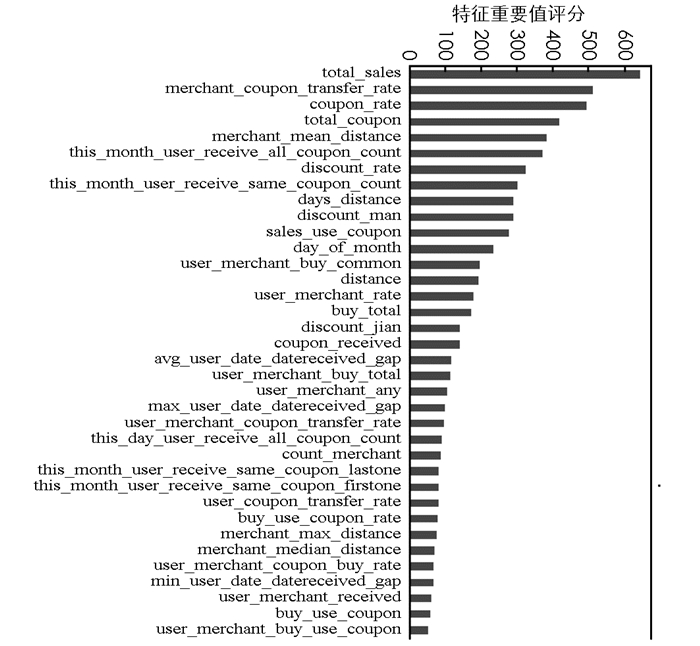
通过XGBoost可以判断每个特征变量对模型的贡献程度, 从中可知哪些特征变量对于用户使用优惠券行为的影响更为显著.分析结果如图 1所示.
由图 1可知, 商户特征集对结果的贡献度最大.商户被消费次数(total_sales), 商户优惠券转化率(merchant_coupon_Transfer_rate), 优惠券消费占总消费比例(coupon_rate), 商户发放优惠券次数(total_coupon), 使用优惠券消费的用户与商户的平均距离(merchant_mean_distance), 这5个商家特征拥有最高的重要性评分, 很大程度上说明商家想要提高优惠券核销率, 需要为消费者提供更大的感知便利性.具体方法可以从两方面着手: ①增加优惠券发放次数, 优化发放渠道; ②缩短线下活动与目标用户群之间的距离, 提高线下网点覆盖率.
优惠券折扣率(discout_rate), 消费日期(day_of_month), 用户从领取优惠券到消费的平均时间间隔(avg_user_date_datereceived_gap), 用户与商户交互的比例(user_merchant_rate), 这些特征也说明省钱体验、客户消费习惯和客户对商家的忠诚度也是消费者使用的重要驱动力.而且, 在节假日之前发放优惠券, 也可以提高优惠券的核销率.
-
为了比较模型的性能, 本文也采用了另外2种常用的分类算法——随机森林和梯度提升树.随机森林(Random Forest), 是利用多棵CART树对样本进行训练并预测的一种分类器.随机森林能处理连续、离散变量, 适用于多分类问题, 在一定程度上可以防止过拟合, 模型稳定性强, 对噪声不敏感, 能并行分布式处理.
GBDT(Gradient Boosting Decision Tree)又叫MART(Multiple Additive Regression Tree). GBDT是一种迭代的决策树算法, 该算法由多棵决策树组成, 将所有树的结果累加起来得出最终答案. GBDT的优点是对离散和连续型变量的处理很灵活, 而且不需要进行特别复杂的特征工程. GBDT的缺点也很明显, 计算复杂度高, 对高维稀疏特征的应用性能较差.
-
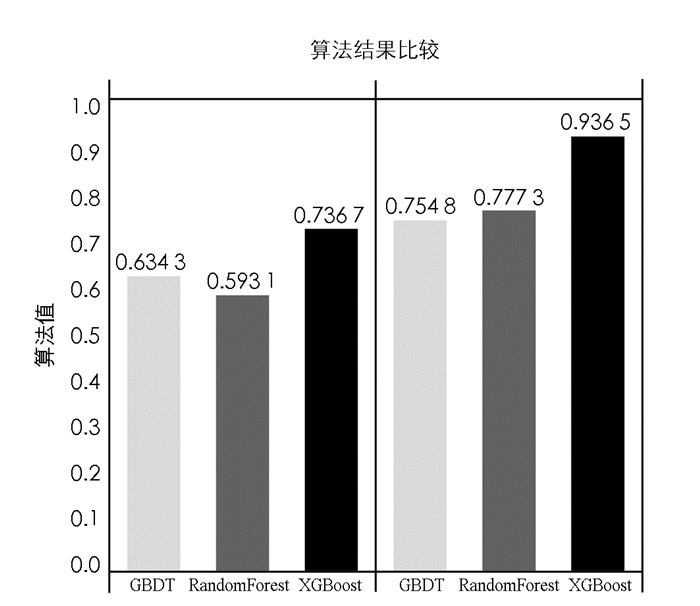
分别采用GBDT, RandomForest和XGBoost对该口碑网爬取的优惠券使用行为数据集进行分类预测, 训练集与测试集的比例均为7:3, 进行多次调参优化后取最好结果如图 2所示.由图 2中显示的AUC score和Accuracy可知, 无论是对准确率和召回率的平衡能力, 还是对0-1标签正确分类的能力, XGBoost对该不平衡数据集的分类效果显著强于RandomForest与GBDT.
3.1. 变量重要性分析
3.2. 其他分类算法
3.3. 算法结果比较
-
优惠券营销作为服务商连接新零售线上线下交易的桥梁, 是一种非常重要的营销新趋势.所以, 预测用户使用情况并改进投放方法是商家面临的重要问题.
本文应用口碑网真实的消费者线上线下交易数据, 突破了大部分研究以TAM模型为理论基础构建个人优惠券使用意愿的传统方法, 并将商户属性、优惠券属性和用户-商户交互属性引入影响因素.通过基于集成学习的XGBoost进行消费券使用行为预测, 并与随机森林、GBDT算法进行了比较, 结果表明XGBoost显著提升了消费券使用的预测准确率.
本文还通过对变量重要性的分析, 确定了对消费者使用决策贡献度较高的变量.该研究有助于理解优惠券核销率的影响因素, 以及用户收到优惠券之后的购买行为决策, 对优惠券的投放与精准营销有重要的现实意义.