


 下载:
下载:
-
随着互联网技术的发展,各个领域海量数据已经成为常态,分析大数据的方法要求越来越高,因此使用机器学习技术探索大规模混合数据成为大数据分析中的一个重要挑战[1-2].鉴于大数据通常由混合类型的属性来描述,需要预处理步骤将数据转换为单一类型,因为大多数提出的聚类方法仅处理数值属性或分类属性.但是,转换策略通常耗时且会导致信息丢失,从而导致聚类结果不准确[3-4],传统聚类算法有K-means和C-means聚类算法等[5-6].
对于大数据处理方法,聚类方法已经得到研究[7],K-prototypes聚类方法[8]中集成了K-means和K-modes方法来聚类数值和分类数据.针对K-prototypes聚类方法的不足,改进K-prototypes聚类方法已经被提出用来处理混合类型的数据,如用于表示群集中分类属性原型的分布式质心概念的引入[9].虽然K-prototypes方法是混合数据执行聚类最流行的方法之一,但该方法还是无法对大规模混合数据进行扩展.
为了处理大规模的数据,现有方法都是在并行框架上进行聚类,大多数方法都使用MapReduce框架,例如MapReduce框架实现的模糊C-means方法[10]、基于单通道和线性时间MapReduce的k-means方法[11]和基于密度聚类与MapReduce的并行化方法[12].虽然以上方法为用户提供了通过MapReduce框架对大规模数据的有效分析,但它们不能支持混合类型的数据,并且仅限于数字属性.因此,通过MapReduce框架下的K-prototypes方法能够并行化处理大规模混合数据[13],然而MapReduce框架与K-prototypes方法具有一个缺陷,在每次迭代过程中都会发生许多I/ O磁盘操作,这会减慢运行时间.
为了解决这个问题,本文提出一种新的基于Spark框架的K-prototypes聚类方法,称为S-KP.本文算法利用Spark提供的灵活性,通过减少内存操作来解决现有MapReduce方案的消耗时间.实验表明,所提出的方法是可扩展的,并且优于现有方法的效率.
全文HTML
-
MapReduce是一个并行编程框架,旨在处理机群聚类中的大规模数据,其特点是对程序员高度透明,允许以简单和舒适的方式并行化算法,要并行化的算法只需要指定2个阶段即map和reduce.每一个阶段中都有<key/value>作为输入和输出,map阶段并行采用每个<key/value>对并生成一组中间<key'/value'>对,然后该框架将与相同中间<key/value>对相关联的所有中间值与列表(称为shuffle阶段)进行分组,reduce阶段将此列表作为生成最终值的输入,MapReduce的输入和输出存储在一个关联的分布式文件系统中,该系统可以从使用聚类的任何一台机器访问.根据可用的聚类体系结构,MapReduce框架的不同实现是可能的.
MapReduce可以在Apache Hadoop上实现,Apache Hadoop是用于商业硬件上大数据处理和存储最受欢迎的MapReduce实现,尽管Hadoop MapReduce非常流行,但在迭代算法中存在问题.
Apache Spark是一种新的大数据处理框架,旨在解决Hadoop的缺点.该框架提出了一套超越标准MapReduce的内存转换,目的是在分布式环境中更快地处理数据,速度比Hadoop快100倍. Spark基于弹性分布式数据集(RDD),这是一种用于以透明方式执行并行计算的特殊类型的数据结构.这些结构持久存储、重用和缓存结果.此外,还管理分区以优化数据放置并使用一系列广泛的转换操作数据,Spark框架的这些功能使其成为大数据处理的有用框架.
-
给定包含n个数据点的数据集X={x1,x2,…,xn},用数据属性mr和分类属性mt来描述. K-prototypes聚类的目的是通过最小化目标函数来找到k个聚类.
其中,uij∈{0,1}是分区矩阵Un*k的元素,表示数据点i在簇j中的隶属度,cj∈C={c1,…,ck}为聚类j的中心,d(xi,cj)是不相似度度量,定义为
xir表示数字属性r的值,xit表示数据点i的分类属性t的值,cjr表示数值属性r和簇j的平均值,计算得
其中,|cj|表示分配给簇j的数据点数量,cjt表示分类属性t和簇j的最常见值,计算方式为
其中,
$f\left(a_{t}^{h}\right) \geqslant f\left(a_{t}^{z}\right), \forall z, 1 \leqslant z \leqslant m_{c}$ ,对于$a_{t}^{z} \in\left\{a_{t}^{1}, \cdots a_{t}^{m_{c}}\right\}$ 是分类值,z和mc是分类属性t的类别数量.$f\left(a_{t}^{z}\right)=\left|\left\{x_{i t}=a_{t}^{z} | p_{i j}=1\right\}\right|$ 是属性值atz的频率计数,对于分类属性,当p=q时,δ(p,q)=0,p≠q时,δ(p,q)=1.
1.1. 大数据技术
1.2. K-prototypes聚类方法
-
本文提出的处理混合大规模数据的方法由Spark框架下的K-prototypes算法并行化实现.首先,输入数据集被分成m个块,然后每个块在map阶段被独立处理,从每个块中提取中间中心,之后reduce阶段处理该组的中间中心以便生成最终聚类中心,这一步被称为重新聚集技术.
为了定义并行实现,有必要定义应用于每个块上的算法以及应用于该组中间中心的算法.对于map和reduce这2个阶段使用K-prototypes算法,对于每个块执行K-prototypes算法并提取k个中心.因此,如果有m块,K-prototypes算法在每个块上都会有一组k×m中心作为中间集合.
为了获得好的质量,记录每个提取中心的分配数据点数量,即从每个块、K中心和分配给每个中心的数据点数量中提取.分配给每个聚类中心的数据点数表示该中心的重要性.因此,必须扩展k-prototypes算法,在对中间中心集合进行聚类时考虑加权数据点.为了考虑加权数据点必须改变中心更新(公式(3)和公式(4)),将wi作为数据点xi的权重,则最终簇的中心使用以下方程计算数值和分类属性.
其中,
$\forall z, 1 \leqslant z \leqslant m_{c}$ .通过Spark框架并行实现K-prototypes算法非常简单.作为输入,从HDFS接收输入数据集X的路径,同时还处理组块数m,组数k.首先,用m块组成的输入数据集X创建一个RDD对象,因此使用Spark框架下的textfile(.)操作.之后,每个map任务选择一大块数据集,在该块数据集上执行K-prototypes算法,并发出提取的中间中心及其权重作为输出.在Spark实现中,使用MapPartition(.)转换,它分别在RDD的每个块上运行k-prototypes算法.当map阶段完成后,一组中间加权中心作为map阶段的输出,并且这组中心被输入到单个reduce阶段,reduce阶段采用中间中心集合及其权重,再次执行k-prototypes算法并返回最终中心作为输出.为了简化这个想法的实现,使用Spark的ReduceByKey(.)转换,当生成最终聚类中心后,将每个数据点分配到最近的聚类中心.
设X-RDD为输入数据集的RDD对象,Xi是与map任务i相关联的分区,Cw={C1w,…,Cmw}为加权中间中心的集合,其中Ciw是从组块i中提取的一组加权中间中心,Cf为最后聚类中心的集合.算法1描述了本文方法的伪代码以及Spark中使用函数的具体步骤.
算法2中给出了K-prototypes算法的具体步骤.
-
为了评估KP-S方法的效率,本文对模拟和实际数据集进行了实验.首先,本文实验比较了所提出的方法、K-prototypes方法和基于MapReduce的K-prototypes(KP-MR)方法[13]的性能.其次,通过分析所提出方法的可扩展性来评估Spark框架的性能.
实验使用Apache Spark版本1.6.2,Apache Hadoop 1.6.0和Ubuntu 14.04实现.实验使用的数据集分为模拟数据集和真实数据集:
模拟数据集:生成4组混合大数据集.数据集范围从500万~1亿个数据点.每个数据点使用5个数字和5个分类属性进行描述.数值是用高斯分布生成的,平均值为350,标准差为100,用数据生成器生成分类值.为了简化模拟数据集的名称,使用符号Sim1,Sim2,Sim3和Sim4分别表示包含500万,1 000万,5 000万和1亿个数据点的模拟数据集.
KDD Cup数据集(KDD):是一个真实的数据集,KDD数据集包含大约500万个数据点.每个数据点都使用33个数字和3个分类属性进行描述.
Poker数据集(Poker):是一个真实的数据集,包含从52张牌的标准牌组中抽取扑克牌的例子,扑克数据集包含大约100万个数据点,每个数据点使用5个数字属性和5个分类来描述.
为了评估所提出方法的质量,使用平方和误差(SSE),旨在测量每个数据点与数据点所属聚类中心之间的平方误差,可定义为
其中,xi是数据点,cj是聚类中心.
为了评估所提出方法处理大规模数据集的能力,在实验中使用加速指标,目的是测量设计的并行方法的扩展能力,计算得
其中,T1是一台机器上处理数据的运行时间,Tm是处理所使用聚类中m台机器上数据的运行时间.
-
在本节中实验比较了本文方法与现有方法的性能,对模拟数据集和真实数据集进行3种算法的性能对比,并在其上应用了S-KP,KP-MR和K-prototypes方法. 表 1是对4个模拟数据集的实验结果,k值取50,表 2和表 3是对2个真实数据集的实验结果,k值取10,50和100.
分析表 1、表 2和表 3中数据可知,本文方法在运行时间上总是比K-prototypes方法和MapReduce上的K-prototypes方法快. 表 3中Poker数据集实验数据中,聚类数量为100时,K-prototypes和MapReduce上的K-prototypes方法比较,本文方法分别可将运行时间减少96.47%和85.72%.
在所有的数据集中,超过95%的运行时间花在map阶段,这表明S-KP方法是真正在内存中执行的,此外,本文方法收敛到和K-prototypes几乎相同的SSE结果,但用时更少.
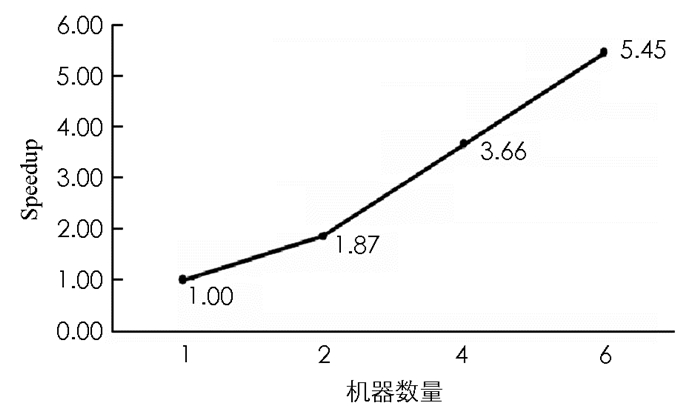
为了研究加速值,本文使用Sim4数据集进行实验,k取值100.首先使用一台机器执行S-KP方法,然后添加额外的机器. 图 1显示了Sim4数据集的加速结果,所提出的方法随着机器数量的增加而呈现线性加速,因为Spark框架具有线性加速并且每个块可以独立处理.
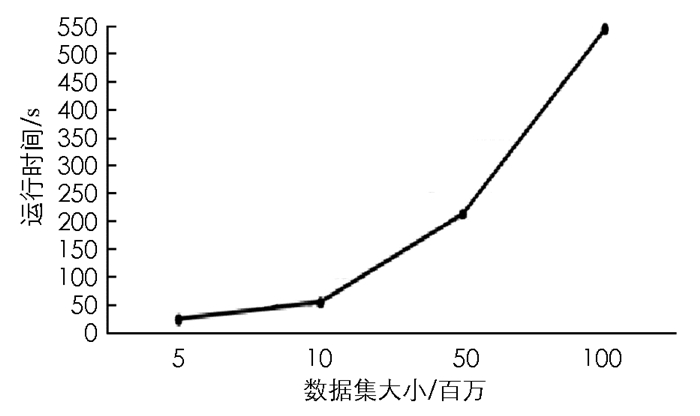
为了研究数据集大小对本文算法的影响,当增加数据集大小时,评估本文方法的可扩展性.实验数据集是模拟数据集Sim1-Sim4,k取值100,结果如图 2所示.
从图 2中可以看出,当数据集大小增加时,运行时间呈线性增长,如KP-MR方法[13]在Sim4数据集上花费超过1 h,而本文方法在不到10 min的时间内处理了数据集.
3.1. 实验数据集及评价指标
3.2. 实验结果分析
-
本文提出了一种新的基于Spark框架的K-prototypes聚类方法,在处理大规模混合数据时,K-prototypes算法有2个主要问题:运行时间和内存消耗. Apache Spark的引入为k-prototypes算法的并行化提供了一个简单、透明和高效的环境.实验结果表明,本文方法是可扩展的,可以提高现有K-prototypes方法的效率.未来的工作是通过使用降维技术,来处理具有大量特征的大规模混合数据.