


 下载:
下载:
-
开放科学(资源服务)标识码(OSID):

-
农业一直是世界各国的经济支柱之一,为全球粮食供应和农村社区提供生计. 然而,传统农业面临着诸多挑战,包括有限的资源、气候变化、土地退化和生态系统破坏等. 在这个背景下,精准农业崭露头角,它是一种农业管理方法,也是确保全世界粮食安全的解决方案之一.
精准农业也称数字农业,是一种以技术为支撑、数据驱动的可持续农场管理系统[1]. 它的核心理念是将数据和技术应用于农业,以使决策更明智、资源更有效地利用、减少浪费,并最终提高农业产量. 精准农业可以应用于各个层面,包括土壤管理[2]、作物种植[3]、灌溉[4-5]和农产品物流[6]等. 精准农业基本采用现代信息技术、软件工具和智能嵌入式设备进行农业决策支持. 机械化农业和绿色革命是第一次和第二次农业革命的两个关键组成部分. 精准农业是第三次农业革命的重要组成部分[7]. 精准农业以定制化和智能化手段提供了更优质的农田管理、资源利用和作物生长监控,有助于农民深入了解土地特性、作物需求及环境因素变化,从而实现农业生产的可持续性和适应性.
精准农业与可持续发展相得益彰、紧密相连. 可持续性是在不损害子孙后代需求的情况下保持一致生产力的经济能力. 可持续农业改善环境质量和资源型农业,其中以人类基本粮食和经济生存能力为基础. 精准农业采用数据驱动的方法来提高农业生产力,并最大限度地减少对环境的影响. 精准农业通过实时收集有关农作物、空气和土壤等农场元素的数据,既保护环境又确保利润和可持续性. 将人工智能技术应用于农业实践具备先进特点,如作物与土壤健康监测、灌溉系统优化、病害识别、杂草控制及推荐措施等. 机器人与传感技术被引入解决了许多与农业相关的问题. 因此,采用机器人辅助农业系统将对作物生产效率和可持续性产生重要影响.
精准农业利用现代信息技术,如物联网[8]、数据分析[9]和人工智能[10]等来提高农业生产的效率和可持续性. 物联网的核心是传感器网络,它对各种农业应用作出了重要贡献. WSN是一种在农业中广泛应用的技术,它通过分布在田地、植被和农田设备上的传感器来实时监测环境参数[11]. 这些参数包括土壤含水量、气温、降雨量、风速、二氧化碳浓度和光照强度等. WSN使农民能够实时收集环境数据,更好地了解农田和作物,帮助他们调整灌溉、施肥和作物保护方法,从而提高生产率并降低资源浪费.
地球上只有近1%的淡水可利用,其中三分之二以冰盖和冰川形式存在于极地. 在发展中国家中,有效利用淡水成为降低成本和提高作物产量的关键问题. 而传统灌溉不仅消耗大量水资源,而且根据地理位置的不同,还可能需要浪费很多时间. 因此,实施精准灌溉是减少水资源浪费,实现可持续性发展农业的有效途径[12].
近年来,许多研究人员设计了基于机器学习的灌溉控制模型,以优化可用淡水资源的使用. Saggi等[13]提出一种利用气候和土壤信息进行周灌溉的智能灌溉决策支持系统. 该系统利用自适应神经模糊推理系统(ANFIS)预测一周的水量. 耿庆田等[14]提出一种线性时间序列模型来预测根区的土壤水分损失. 虽然这些模型在灌溉控制方面效果较好,但与数据分析技术相结合,导致其校准更加耗时,且仅限于校准的特定区域. Navidi等[15]提出一种使用支持向量机(SVM)和相关性向量机模型预测田间土壤含水量的数据驱动方法. Huerta-Bátiz等[16]将数据同化与SVM相结合,提出一个基于卡尔曼滤波器的模型来预测不同深度的土壤含水量. 这些模型在预测土壤含水量方面表现良好,但存在数据预处理步骤过于耗时和依赖用户干预的问题. Jimenez等[17]提出长短时记忆(LSTM)降雨-径流模型,并利用流域属性(大样本训练数据集)对其进行校准,将其性能与土壤水分核算模型进行了比较. 然而,这些提出的模型主要是感知来自传感器的原始信息的质量,但没有讨论如何准确处理实时信息以预测土壤含水量.
基于以上研究,本文结合物联网和人工智能技术,提出一种利用无线传感器网络基于T-S模糊逻辑的智能灌溉调度系统,通过验证并与现有最先进的灌溉系统进行比较,结果证明了本文灌溉调度系统在精准灌溉调度方面的可行性和有效性.
本文的主要目的是探讨如何在精准农业中实施物联网和人工智能技术,以支持农业可持续发展. 我们关注的核心问题是智能灌溉调度,它是农业领域中的一个关键应用. 同时,我们将探讨如何利用离散仿射Takagi-Sugeno(T-S)模糊逻辑控制来开发一个智能灌溉系统,该系统可以通过数据分析和智能决策来管理农作物的水资源利用,以实现高效灌溉,减少水资源浪费,提高作物产量.
本文的创新之处主要体现在以下几个方面:
1) 将离散仿射Takagi-Sugeno(T-S)模糊逻辑控制引入智能灌溉系统,这是一种在农业领域尚未广泛应用的控制方法.
2) 传统的智能灌溉系统通常依赖于基础的控制方法,而本文提出的方法可以更好地处理模糊性和不确定性问题.
3) 使用传感器网络收集环境数据,如土壤含水量、气温和降雨量等,并利用这些数据来实现智能决策,以调整灌溉水量和时间.
全文HTML
-
作物水分胁迫指数(CWSI)被引入并广泛用于衡量作物水分胁迫的程度[18]. CWSI可分为两大类,即经验CWSI和理论CWSI. 经验CWSI为实际冠层温度与非水分胁迫基线之间的差异,该差异通过公式(1)计算,并由水分胁迫基线与非水分胁迫基线的差异进行归一化.
其中,CWSIE为经验CWSI. Nc为实际作物冠层温度,单位为摄氏度(℃). Ntms为充分灌溉作物以最大速率蒸腾时获得的非水分胁迫基线,单位为摄氏度(℃). Ndry为非蒸腾作物冠层获得的水分胁迫基线,单位为摄氏度(℃). 然而,Ntms和Ndry需要额外的人工湿和干参比面,导致CWSI在实际实施中的潜在使用受到限制.
因此,基于温度基线而非人造表面的预测,本文提出并发展了理论CWSI. 理论CWSI的表达为:
其中,CWSIN为理论CWSI. ΔNw为冠层温度和空气温度之间的温差(Nc-Ng). ΔNl为冠层温度和充分灌溉作物冠层温度之间的温差,如公式(3)至公式(6)所示. ΔNp为冠层温度和非蒸腾作物冠层温度之间的温差. ΔNp可通过假设非蒸腾冠层的气孔关闭,并在公式(7)中将aq替换为零来计算.
其中,Rt为净辐射. γ为湿度常数. Δ为饱和蒸气压与空气温度之间关系的斜率. Ug为大气压力. QUD为蒸气压差. αS和αL分别为短波和热波段的吸收率. gH为空气边界层对热的导热率. Cu为空气热容. εg为天空发射率. σ为斯蒂芬-玻尔兹曼常数. Ng为以开尔文为单位的空气温度. vq为蒸气导电. Sr为全球太阳辐照度. τ为绿叶透射率. Lg为使用斯蒂芬-玻尔兹曼方程计算的大气长波通量密度. p为风速. d为叶宽0.72倍的特征尺寸.
如公式(1)和公式(2)所示,CWSI值为0~1,其中CWSI为0表示水分充足,而CWSI为1表示缺水状况. 因此,CWSI可用于定量评估作物水分状况,并作为灌溉调度的简单指标.
-
土壤含水量(θ)是灌溉管理中的一个关键变量. 土壤含水量可用于估算土壤中的水分,通常可以通过质量法测定土壤含水量. 然而,质量法是基于对土壤含水量的直接测量,这是一种破坏性和费力的方法. 因此,质量法不能用于实时测量和应用. 在过去的几十年中,学者们提出并应用了间接方法,采用电容和频率技术来开发土壤湿度传感器,这种类型的传感器称为电容式土壤湿度传感器. 电容式土壤湿度传感器利用土壤介电特性来确定土壤含水量,通过将其电极插入土壤,可以得到土壤介电常数. 然后将测得的土壤介电常数转换为体积土壤含水量. 体积土壤含水量用单位体积土壤中立方厘米的水体积表示. 因此,体积土壤含水量(θ)为0~100,单位为m3/m3或%.
基于电容和频率技术,电容式土壤湿度传感器与其他仪器相比具有多种优势,例如成本更低、并具有连续监测和数据记录功能等. 由于这些优点,电容式土壤湿度传感器在农业中被广泛应用于许多领域.
-
测量数据中通常包含与测量设备能力相关的噪声. 在使用数据之前,应对测量数据进行处理以消除噪声. 用于时间序列数据最简单的技术是基于简单移动平均(SMA)来消除噪声. 然而,SMA通常会产生滞后问题. 因此,为了减少滞后,通过在历史数据上添加指数权重来开发指数移动平均(EMA). EMA可以通过以下公式来定义.
其中,j(z)为在时间点z上某个数据序列的指数移动平均值,j(z-1)为前一时刻z-1观测到的特定数据点上的数据指数移动平均值. α为平滑系数,值为0~1. t也是在EMA中使用的数据点数. (1-α)为EMA公式中的一部分,表示历史数据的权重.
在实际应用中,数据处理方法和策略对于确保数据质量和可解释性至关重要. 数据点数量t的选择取决于测量数据的波动性. 气候数据通常被定义为高波动数据,需要较多的数据点进行平滑处理,以减少短时间内大幅波动对分析结果的影响. 土壤含水量数据被定义为低波动数据,可以采用较少的数据点,降低计算成本,同时保持数据趋势的准确性. EMA技术的应用在数据处理中起到至关重要的作用,不仅可以使数据更加平稳,减少噪声干扰,还可以在传感器或电气系统故障时对数据进行修复. 通过定义更多数据点来过滤环境传感器获取的气候数据,可以更好地捕捉气候变化的瞬时波动,提高数据分析的准确性和可靠性.
1.1. 作物水分胁迫指数
1.2. 土壤含水量
1.3. 噪声过滤技术
-
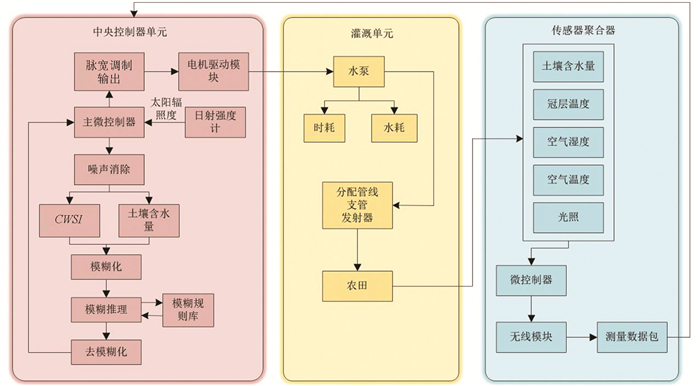
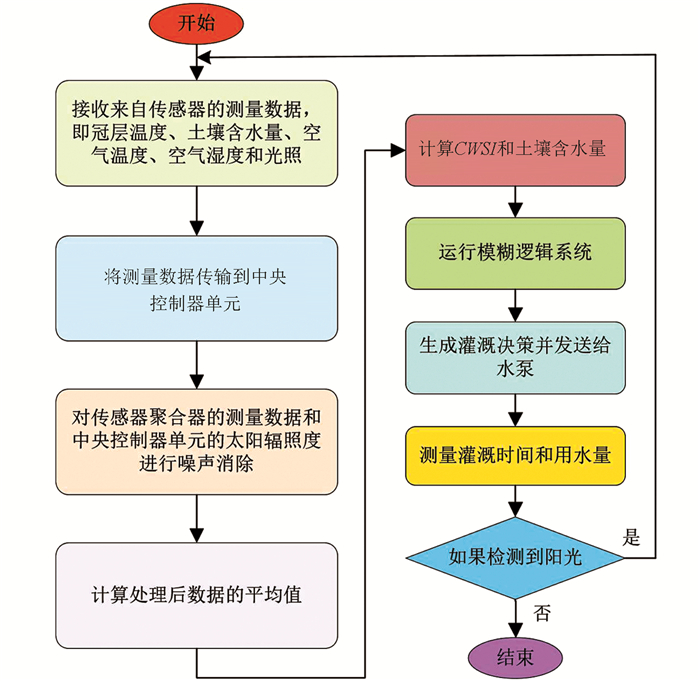
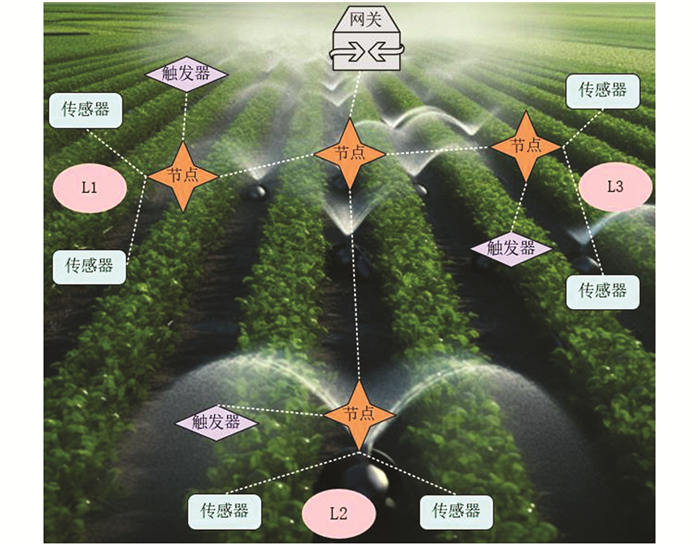
本文提出的智能灌溉调度系统分为3个主要部分,包括传感器聚合器、中央控制器单元和灌溉单元(图 1). 传感器聚合器收集土壤湿度和气候数据,并通过无线传感器网络传输到中央控制器单元. 中央控制器单元接收来自传感器聚合器的测量数据以及太阳辐照度,然后将接收到的数据进行噪声消除与平均值处理,用于计算CWSI和土壤水分含量. 系统接收CWSI和土壤水分含量信息,并考虑作物和土壤的变化,采用本文设计的模糊逻辑系统做出灌溉决策,并向灌溉单元中的水泵发出控制信号. 然后,将测量结果整合起来,以评估本文所提出系统消耗的水量和时间.
-
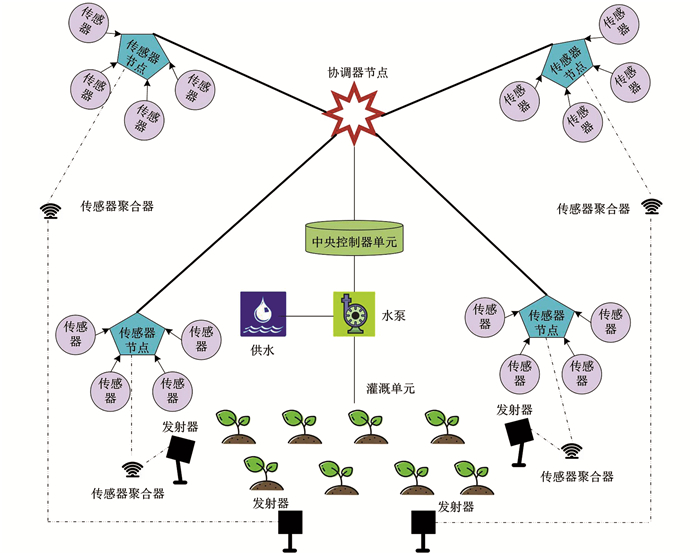
传感器聚合器负责作为WSN中的传感器节点. 聚合器中嵌入了环境传感器,包括土壤湿度传感器、空气温度传感器、相对湿度传感器、光传感器和红外温度传感器. 土壤含水量使用土壤湿度传感器SKU:SEN0193测定. 环境空气温度和相对湿度的测量采用温度/相对湿度传感器DHT22,并使用GY-906(MLX90614ESF)红外温度传感器测量作物冠层温度. Arduino UNO R3板用作主微控制器,以聚合传感器测量相关数据. 此外,传感器聚合器包含在防水塑料容器中,以保护天气. 该灌溉调度系统还采用了WSN的可用性,以加强实践中的实施. 在实际实施中,单个测量数据无法准确地描述实际现场数据的平均变化. 为了解决这个问题,本文使用了两个传感器聚合器. 传感器聚合器能够使用NRF24L01收发器模块将传感器获得的测量数据发送到中央控制器单元,以实现通信协议. 使用NRF24L01收发器模块是因为其消耗超低,更简单,更便宜. 该模块整合了2.4 GHz射频收发器、射频合成器和基带逻辑,同时配备了增强型ShockBurstTM硬件协议加速器,这些特性使得模块能够通过高速通用串行外设接口(SPI)与应用程序控制器进行高效通信. 然而,NRF24L01只能传输100 m以内的数据. 在这项工作中,本文选择了带有功率放大器/低噪声放大器的NRF24L01,以提高从NRF24L01模块传输的信号的功率(高达1 000 m). 该灌溉调度系统利用并实现了基于星形拓扑的WSN,如图 2所示. 为了节省传感器聚合器消耗的电力,本文采用浅照度传感器BH1750FVI在白天自动打开,在夜间自动关闭,从而防止对作物造成破坏性伤害. 在通常情况下,大部分蒸腾活动(水分从树叶中流失)发生在白天,任何水分在夜间都不能被气孔排出. 由于水分滞留在作物上,使病原菌渗入,造成叶片腐烂和其他破坏性损伤.
-
中央控制器单元作为WSN中的协调器节点,负责接收和传输传感器节点的数据,并作为灌溉(外部)系统进行灌溉调度. 在WSN的角色中,中央控制器单元接收了前述聚合器获取的时间序列数据. 另一方面,作为协调器节点的中央控制器单元将数据转发到灌溉调度系统(外部). 在灌溉调度系统角色中,转发的数据将在智能灌溉调度系统中进行处理.
本文所提出的智能灌溉调度系统采用土壤含水量和CWSI作为模糊逻辑系统的输入变量,如图 1所示. 土壤含水量用于表示土壤水分的变异性,可通过土壤湿度传感器测量. 传统上CWSI的计算需要通过人造作物表面获取温度基线. 然而,人造作物表面限制了CWSI在实际应用中的使用. 本文采用理论CWSI获得作物的水分状况. 为此,需要空气温度、相对湿度、作物冠层温度和太阳辐照度来计算公式(2)中的理论CWSI. 这些测量值由传感器聚合器提供,太阳辐照度除外. 因此,除了嵌入在传感器聚合器中的传感器外,在中央控制器单元上还安装了光辐射计BGTJYZ2测量太阳辐照度. 由于太阳辐射根据太阳和天气决定,因此本文仅在中央控制器单元上安装一个日射强度计来降低投资成本.
在对所有数据进行计算之前,使用公式(8)和公式(9)中的EMA技术处理测量数据,以消除数据中包含的噪声. EMA技术的数据点数量根据测量数据的特性定义. 由于有两个传感器聚合器,因此将计算处理后的测量数据取平均值. 将处理后的测量数据用于计算CWSI. 计算得到的CWSI和土壤含水量将作为模糊逻辑系统的输入变量. 而模糊逻辑系统发布的基于知识设计的灌溉决策,将驱动灌溉单元的泵.
-
在本文中,灌溉单元使用表面滴灌. 灌溉单元由供水、泵、阀门、分配管线、支管和发射器组成. 根据中央控制器单元发布的灌溉决策,可以通过基于脉宽调制的泵驱动来改变泵的速度,从而调节水压. 本文还考虑了水能源效率,为了测量用水量,安装了水流量传感器. 此外,能耗通过对每种灌溉策略电机运行随时间推移消耗的电力进行积分来计算. 因此,安装电压和电流测量装置可获取电机的电压和电流数据. 然后,使用电压和电流数据来计算电机的电力,所得功率用于计算能量. 图 3提供了本文所提出的智能灌溉调度系统的工作流程.
-
在传感器聚合器中,采用了基于介电特性的电容式土壤湿度传感器. 为了计算CWSI指数,使用红外温度传感器并将其嵌入防水塑料容器内. 此外,测算指数还需要空气温度和湿度传感器的数据. 光传感器也被应用于阳光检测,并能在夜间自动关闭. 安装无线模块是为了将测量数据发送至中央控制器单元,而在中央控制单元上则配备有日射强度计以测量太阳辐照度.
-
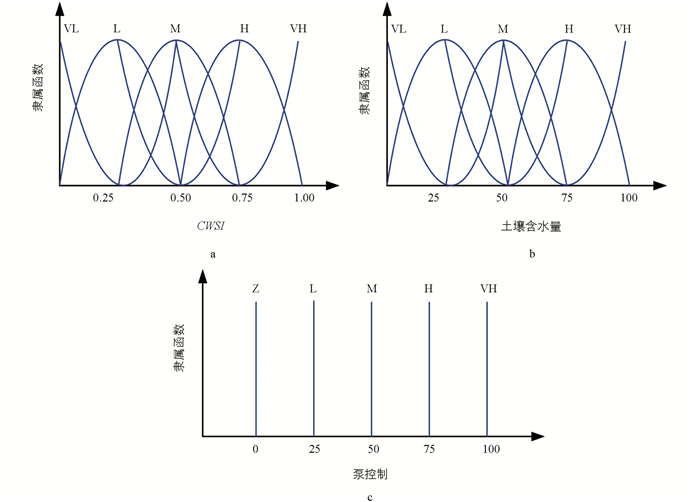
本文将T-S模糊逻辑系统应用于灌溉调度系统. 模糊逻辑系统由3个主要过程组成,即模糊化、模糊推理和去模糊化. 模糊逻辑系统的概述如图 1所示. 在模糊化过程中,根据隶属函数将CWSI和土壤含水量转换为模糊逻辑. 本文采用了一组对称三角隶属函数,CWSI的隶属函数和土壤含水量如图 4所示. 由于CWSI值为0~1,因此CWSI的隶属函数分为5种类型,即极低(VL),低(L),中(M),高(H)和非常高(VH),如图 4(a)所示. 土壤含水量值为0~100%,因此土壤含水量的隶属函数也分为非常低(VL)、低(L)、中(M)、高(H)和非常高(VH)5种类型,如图 4(b)所示. 模糊推理是基于知识库设计的一种方法,用于评估模糊规则并为每个规则生成相应的输出. 该规则库根据CWSI和土壤含水量这两个输入进行设计.
在去模糊化过程中,多个输入根据规则库和输出隶属函数转换为清晰的输出. 模糊系统的输出目标是生成用于控制灌溉装置中水泵的信号. 通过中心平均法,将模糊系统的输出转化为清晰明确的结果. 模糊输出隶属函数采用单例输出隶属函数,因此输出隶属函数分为5种类型,即零(Z)、低(L)、中(M)、高(H)和非常高(VH),如图 4(c)所示. 如果作物水分胁迫指数(CWSI)高且土壤含水量低,则水泵以75%的功率运行. 如果CWSI高且土壤含水量非常高,则泵停止工作.
2.1. 智能灌溉调度系统设计
2.1.1. 传感器聚合器
2.1.2. 中央控制器单元
2.1.3. 灌溉单元
2.2. 智能灌溉系统实施
2.3. 模糊灌溉调度策略
-
使用Python 3.8.1软件对土壤含水量预测进行仿真实验. Numpy和pandas库用于数据预处理和数据管理. 以秦岭-淮河以南的江苏南部地区作为本实验的测试地点. 从中国气象部门获得测试地点的气象数据,包括气温、空气湿度和降雨量,时间跨度为2021年6月1日至2022年12月31日,共578 d数据,可以捕捉到整个年周期的时间动态. 所有地点的土壤含水量和土壤温度均由宇宙射线土壤湿度传感器(型号CRS-1000/B)测量,其水平范围为200 m,土壤水分测量深度达20 m. 获得的数据被重新采样为每日平均值(24小时)并输入本文系统,以预测所有站点下一天的土壤含水量. 为了避免网络过拟合,每个站点的数据集被分成70∶30的比例,即433 d的数据用于训练,剩余的145 d数据用于测试.
选择秦岭-淮河以南的江苏南部地区作为测试地点有几个重要原因:①该地区具有丰富的农业活动,对精准农业研究具有实际应用的重要性. ②该地区气候条件在全年范围内变化较大,从气温、空气湿度到降雨量,为研究工作提供了多样化的气象数据,有助于模型的全面测试和验证. ③选择宇宙射线土壤湿度传感器进行土壤含水量和土壤温度测量,其水平范围和测量深度较大,能够提供详尽的土壤信息,有助于研究系统的精确性. 这个选择保证了研究工作的实际性和广泛适用性,使所得结论更具有推广和应用价值.
为了对比性能,本文考虑了两个最先进的模型,即文献[19]模型和文献[20]模型. 文献[19]模型每天预测土壤水分含量的体积,并估计灌溉时间和用水量,以保持土壤含水量在预定义范围内. 在文献[20]模型中,灌溉期间对土壤含水量进行连续监测,根据简单规则控制执行器打开或关闭水阀:
其中,β=1表示水阀打开,β=0表示水阀关闭. avg(SW(n))为第n天的平均土壤含水量测量值. SnbW为农民定义的土壤含水量目标值的阈值. g=1,…,G为不同的规则或区域.
为了量化最新模型的性能,使用了两种类型的尺度:
(ⅰ) 定量性能尺度用于估算节水量,表示为:
其中,
$ \widetilde{Q(n)}$ 为用于评估水量百分比改善的基准水量,以衡量模型节水的水量;Q(n)是实际水量,表示系统使用的水量.(ⅱ) 定性性能尺度用于以水分亏缺Ψ(n)形式测量作物生长速率(mm),表示为:
水分亏缺由专业农民通过观察作物叶片颜色和树枝生长来进行测量. low:指作物处于较严重的水分亏缺状态,即土壤含水量小于15 mm. 这种情况下,作物可能需要及时灌溉来避免水分不足对生长产生不良影响. medium:指作物处于中等水平的水分亏缺状态,即土壤含水量在15 mm至70 mm之间. 作物此时的水分亏缺不严重,但可能会影响一定程度的生长. high:指作物水分亏缺较轻微或不存在,即土壤含水量大于70 mm. 作物此时水分供应充足,生长状况良好,暂时不需要灌溉.
为了进行实验验证,本文创建了一个包含9个感知节点、3个锚节点和3个执行器的无线体系结构,部署在面积为12×102 m2的农田区域(L1). 感知节点部署在作物附近,执行器安装在电动水阀附近,根据灌溉计划打开或关闭它们. 农田区域分为3个子区域,以便使用不同的最新模型进行比较分析(图 5). 第一个农田区域(L1)用于本文系统,第二个农田区域(L2)用于文献[19]模型,第3个农田区域(L3)用于文献[20]模型.
-
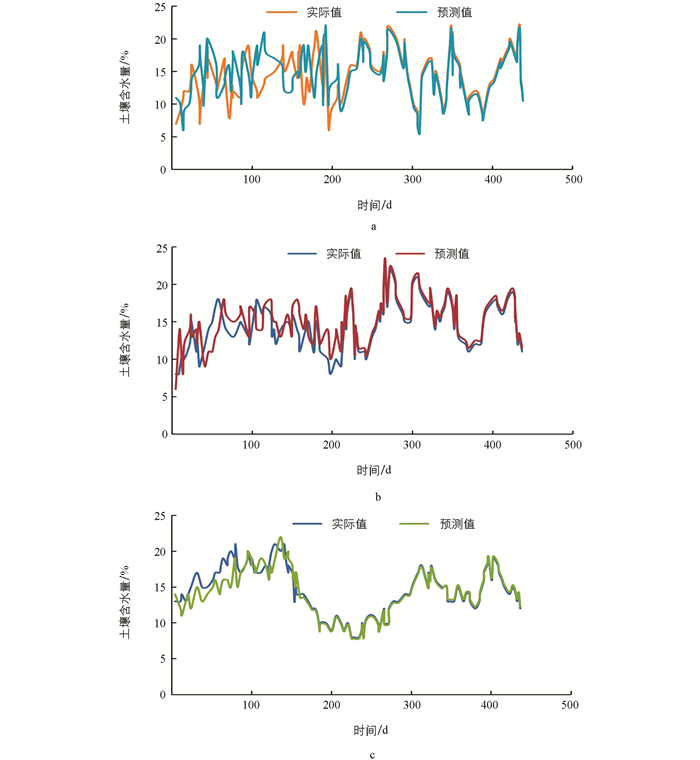
图 6(a、b、c)中的结果显示了在3个不同测试站点的433 d(训练期)内设置α=0.8时,预测土壤含水量相对于实际测得土壤含水量的情况. 根据结果可明显观察到,在年初阶段土壤含水量预测值与实际值存在较大波动,这一现象可以归因于本文系统在行为上的初步简单性以及对站点特征了解不足. 随着训练期(天数)增加,预测值逐渐接近实际值,这一观察证实了本文提出的智能灌溉系统学习能力高于基础动态时间信息. 体积土壤含水量为12%~24%.
本文提出的智能灌溉系统对3个不同测试站点的预测/验证性能如表 1所示. 其中,RMSE为体积土壤含水量的均方根误差.
从表 1的均方根误差值可以看出,本文系统可以对每个测试站点的体积土壤含水量作出准确(接近于零)的预测. 这一结果证明,本文系统进行预测可进一步提高各种作物在生长过程中的节水量.
在试验农田中对水量估算和灌溉时间进行验证. 在相同的初始条件下,本文系统、文献[19]模型和文献[20]模型分别安排了3次独立灌溉. 体积土壤含水量通过试验观测设定为14%~24%,以保证作物的充分生长. 图 7显示了本文系统与其他灌溉系统在一个灌溉期的土壤含水量对比情况. 对于未来一天的土壤含水量预测,可将前一天的气候信息和土壤信息输入到本文系统、文献[19]模型和文献[20]模型中来监测土壤含水量.
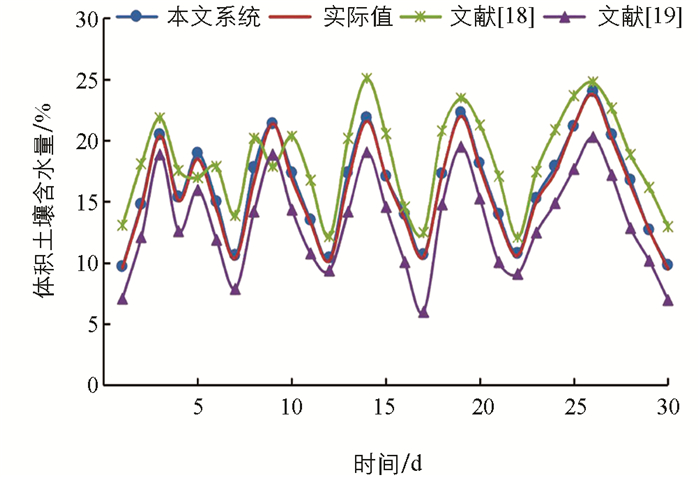
与文献[19]模型、文献[20]模型相比,本文系统的土壤含水量能很快达到22%的参考含水量,这是因为本文系统比最先进的模型能更好地处理时间输入. 文献[20]模型在节水量方面表现最差,因为较长的灌溉期会超过土壤最大保水能力,最终超过体积土壤含水量(>24%). 将公式(11)计算得出的节水量作为定性指标,本文系统相较于文献[19]模型和文献[20]模型分别增加了22.75%和44.28%.
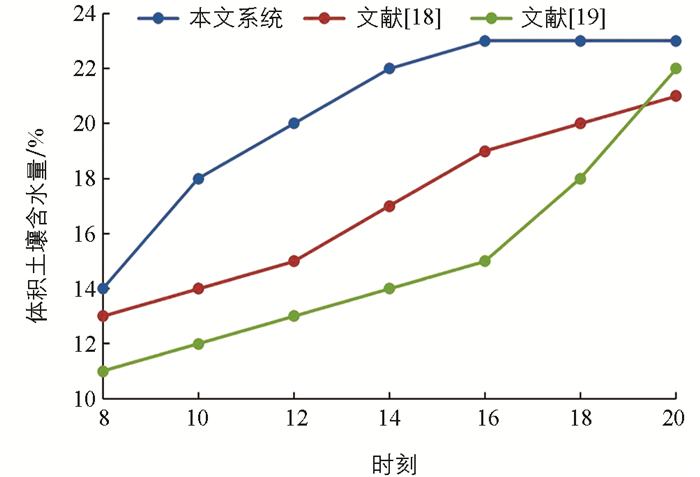
图 8显示了3种模型在测试地点一个月的总灌水量预测对比分析. 由于本文系统形成了一个闭环系统,同时接收来自土壤湿度传感器和温度传感器的反馈,因此可以预测接近实际测量值的土壤含水量. 此外,本文系统通过处理时间信息可将土壤含水量预测为准确值,而文献[19]模型在开放形式的系统中,其复杂的隐神经元处理特征无法准确预测接近测量值的土壤含水量. 从图 8还可以观察到,在L1中使用本文系统预测出的土壤含水量值在一个月内平均为16.2%,文献[19]模型预测出的L2土壤含水量平均值为18.4%,文献[20]模型在L3中预测的平均土壤含水量为13.3%,而实际测量值为15.9%,意味着两种对比方法与实际值都有一定差距,只有本文系统最接近实际值. 实验结果表明,当土壤含水量低于预定阈值时,本文系统会对自然界的剧烈变化做出快速反应,并以最佳水量触发灌溉计划.
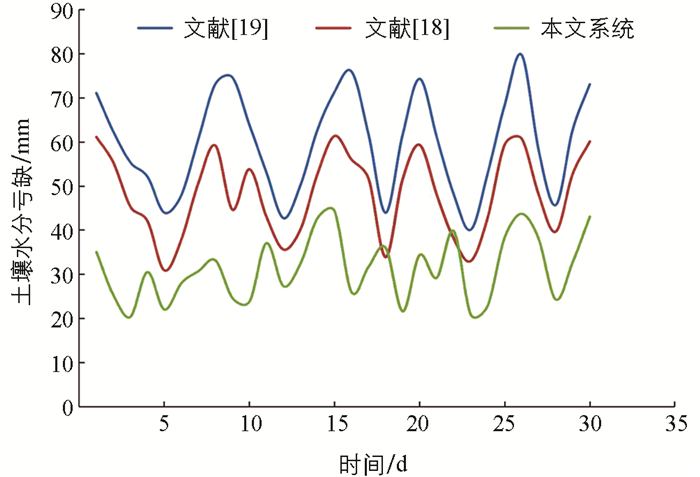
图 9显示了3种模型对土壤水分亏缺的量化分析比较. 本文系统测得大部分天数的土壤缺水量都在中等范围内(20 mm≤snmd≤40 mm). 这一结果证明本文系统能够准确预测土壤含水量,并节约更多的水. 在文献[20]模型中,土壤缺水量的负值表示浇水过量,即土壤含水量高于框架面积容量. 在文献[19]模型中,土壤缺水量在一个月内的变化范围大多在30 m≤snmd≤60 mm范围内,文献[20]模型在40 mm≤snmd≤75 mm范围内. 这一观察结果验证了文献[19]模型相较于文献[20]模型能更好地节约灌溉用水,因为文献[19]模型利用网络隐藏层和权重调整来预测土壤含水量. 总体而言,本文提出的模型能够将土壤水分亏缺保持在指定范围内,并且适时调整灌溉计划以促进作物生长.
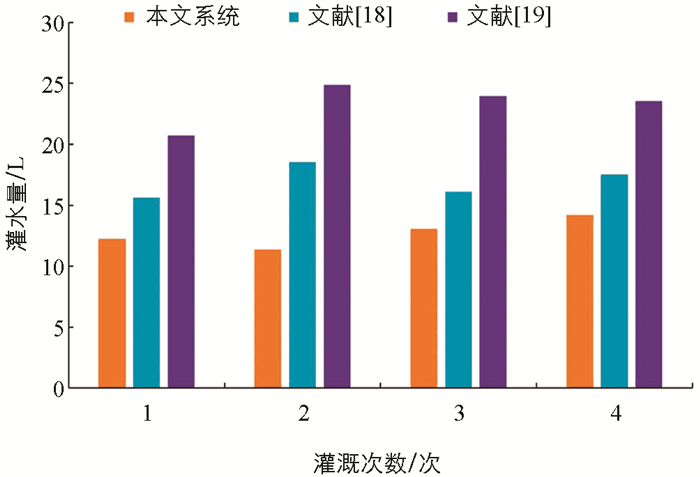
图 10显示了3种模型在一个月中不同周期的灌水量情况. 3种最先进的模型一个月的灌溉计划都是4次,这是因为预测的土壤含水量在规定值范围内,只有当土壤缺水量低于阈值时才需要灌溉. 从图 10可以看出,本文系统的平均水量约为12.72 L,基于文献[19]模型和文献[20]模型的平均水量分别为16.96 L和23.28 L. 与其他两个先进的对比模型相比,本文系统在这4次灌溉计划中平均节约的水量分别为25%和45%. 这是因为本文提出的智能灌溉调度系统能够根据土壤含水率和CWSI变异性进行精确灌溉调度,从而有效地估算作物生长所需的灌溉时间和水量,最终为农民带来经济效益.
3.1. 实验设置
3.2. 结果分析
-
随着全球人口对食物和水资源需求的不断增长,精准农业引起了极大的关注. 灌溉计划自动化是精准农业系统的主要任务之一. 因此,本文提出一种基于离散仿射T-S模糊逻辑的无线传感器智能灌溉调度系统. 为实现智能灌溉调度,本文采用了T-S模糊逻辑控制方法,该方法融合了模糊逻辑与灌溉系统之间的复杂关系,充分考虑了土壤含水量、气象条件、作物需水量等多维数据. 实验结果表明,本文提出的智能灌溉调度系统可以使土壤含水量和作物水分亏缺保持在适当水平内,与其他现有先进模型相比,具有更高的可靠性和高效性. 由此得出结论,本文系统能够准确预测土壤含水量,同时提高用水量和效率,从而助推精准农业可持续发展.
尽管本文提出的系统在可持续精准农业发展中具有广阔的应用前景,但也面临一些挑战:①系统的性能应在实际农田中进行验证,这需要大规模的实验和数据收集,以确保系统的稳定性和可靠性. ②系统需要考虑多样化的农田和环境条件. 不同的农田可能需要不同的模糊规则和参数设置. 因此,需要进一步的研究来适应不同情境. 未来的发展方向包括优化系统模糊逻辑控制算法,以提高决策的精确性和效率. 可以考虑引入更多的传感器类型,如图像传感器等,以获取更多的环境信息. 此外,还可以将系统与农业机械和设备集成,以实现更高度自动化的农田管理.