


 下载:
下载:

-
开放科学(资源服务)标志码(OSID):

-
Zadeh[1]在1979年首次提出信息粒化的概念,认为人类认知能力可概括为粒化、组织和因果3个主要特征,并由此引出粒计算的概念. 目前粒计算已成为智能信息处理领域的一个热门研究方向,在复杂问题求解、海量数据挖掘和模糊信息处理中具有独特优势. 它模拟人类思考方式,以粒为基本计算单位,强调对问题多角度、多尺度的理解和描述. 由波兰学者Pawlak[2]提出的粗糙集理论是一种处理不精确、不确定信息的数学工具,其利用等价关系诱导的划分粒化数据样本集,使用由等价类描述的粒代替样本对数据进行表示和处理,并通过约简对数据集进行特征提取[3]. 在众多粒计算研究方法中,粗糙集理论对推动和发展粒计算研究发挥着重要的作用.
现实世界中由于数据测量的误差、对数据的理解或获取的限制等因素,使得数据呈现不完备性. 如何科学地处理数据的缺失是当前知识发现领域的难点之一. 使用粗糙集理论处理不完备信息系统(incomplete information system,IIS)的方法大致分为两类:①间接处理,即采用数据补齐或数据删除将IIS转化为完备信息系统[4-5]; ②直接处理,即将粗糙集模型在IIS中进行扩展. 就目前关于IIS的研究来看,一般都是将未知属性值分为“缺席型”和“遗漏型”两种语义进行讨论. 其中,缺席型未知属性值指存在且有用的缺失值,只是由于某种原因而丢失或者没有获取到; 遗漏型未知属性值指对决策或分类结果没有影响的缺失值,被称为“不关心”条件. 针对IIS中所有未知属性值都是缺席型的情况,Stefanowski等[6]构建了相似关系(自反性和传递性). 当IIS中所有未知属性值都是遗漏型时,Kryszkiewicz[7]构建了满足自反性和对称性的容差关系. 然而无论是相似关系还是容差关系都只考虑了未知属性值的一种语义解释,为了处理同时包含遗漏和缺席型未知属性值的IIS,Grzymala-Busse[8]利用改进的属性-值对构建其中的特征关系,此广义不可分辨关系是结合容差关系和相似关系的一种更为一般的表现形式. 此后,学者在IIS中进一步研究了特征关系[9-11].
在传统的粗糙集数据分析模型中,一个对象在每个属性下只能取唯一的属性值,这样的数据描述结构称为单粒度信息系统. 然而,单一粒度或单一尺度结构下的知识表示和数据挖掘已不能满足实际应用的需求. 因此,Qian等[12]提出多粒化粗糙集模型,认为多粒度是由属性选择引起的,该模型根据信息系统中多个属性子集构成知识多粒度空间; Zhu等[13]以邻域粗糙集为基础提出多粒度邻域粗糙集模型,根据对象邻域半径的大小对论域进行粒化,然后选择合适的粒度进行分类或聚类. 多粒化粗糙集模型和多粒度邻域粗糙集模型处理的数据形式实质上还是单尺度的. 然而在实际应用中,对象在同一属性下根据不同的需求以不同的尺度进行测量会取不同的属性值,而在不同尺度下进行决策可能会导致不同的结果. 基于这一情况,Wu等[14]认为对象的属性取值的多尺度是引起论域的多粒度粒化的一个原因,由此提出多尺度数据的粒计算分析模型,并进一步讨论了最优尺度选择和规则获取问题[15-16].
She等[17]研究了多尺度信息系统的局部最优尺度和规则提取. Chen等[18]和郑嘉文等[19]从信息熵的角度分别讨论多尺度覆盖决策系统和多尺度决策系统的最优尺度选择问题. Zhang等[20]在考虑不确定性的同时,结合代价敏感选择最优尺度. She等[21]通过引入粒度树和切割的概念在多尺度决策系统中定义了最优切割,又进一步讨论了泛化约简[22]. Wang等[23]在多尺度信息系统中构建多粒度粗糙集模型以选择最优尺度. 上述研究假设所有属性拥有相同的尺度级数[14-23],Li等[24-25]提出广义多尺度信息系统的概念,即不同属性可以拥有不同数目的尺度级数,并研究了最优尺度组合选择问题. 此后,许多学者也对最优尺度组合进行了研究[26-28]. Hao等[29]基于三支决策的思想在多尺度决策系统中构建序贯三支决策模型,并基于该模型在动态变化的多尺度决策系统中选择最优尺度. 上述关于多尺度信息系统的研究只针对完备数据,于是Wu等[30]将容差关系引入到多尺度信息系统中以应对数据的缺失,并进一步研究最优尺度选择和规则获取问题[31-32]. 顾沈明等[33]在不完备多粒度决策系统中研究了局部最优粒度选择问题.
现有关于不完备多尺度信息系统的研究只考虑了遗漏型未知属性值,并且假设对象在某个属性下缺失时则在该属性的所有尺度下全部缺失[30-33]. 此外,系统的不确定性随着尺度细化存在保持不变后减小的情况,此时Hao等[29]选择的最优尺度的不确定性不是最小. 考虑到上述情况,本研究定义混合语义下的不完备多尺度信息系统,即未知属性值包含两种语义解释且对象在属性下的缺失既可以全部缺失也可以部分缺失,并且融合数据填补和模型扩展的方法以处理此类更为一般的不完备多尺度信息系统. 最后建立序贯三支决策模型,利用三支决策表示决策系统的不确定性,基于该模型给出最小化不确定性的最优尺度选择方法.
全文HTML
-
本节主要介绍基于特征关系的不完备信息系统以及基于容差关系的不完备多尺度信息系统的基本概念.
定义1 [8] 信息系统S可以表示为一个二元组(U,A),其中U={x1,x2,…,xn}是一个非空有限对象集,称为论域; A={a1,a2,…,am}是一个非空有限属性集,对于任意的a∈A,满足a:U→Va即a(x)∈Va,x∈U,其中Va={a(x)|x∈U}称为a的值域. [(a,v)]为属性-值对(a,v)的块,记:
定义2 [8] S=(U,A)是一个不完备信息系统,Va={a(x)|x∈U}为属性a∈A的值域. 符号“*”和“
$ \mathit{\emptyset} $ ”分别表示遗漏和缺席型未知属性值. 对于属性-值对的块[(a,v)],有:①若a(x)=*,则x∈[(a,v)]; ②若a(x)=$ \mathit{\emptyset} $ ,则$x \notin[(a, v)] $ . 其中$ \forall x \in U, a \in B \subseteq A$ ,记:K(x,a)为x关于属性a的不可分辨对象集,则特征集KB(x)定义为:
对于∀x,y∈U,特征关系RB为U上关于属性子集B
$ \subseteq $ A的广义不可分辨关系,记:显然,特征关系RB仅满足自反性,而不一定满足对称性和传递性. 若IIS中的所有未知属性值都是遗漏型,则特征关系RB退化为容差关系[7]; 若IIS中的所有未知属性值都是缺席型,则特征关系RB退化为相似关系[6]. 因此,可以将特征关系看作是容差关系和相似关系的一种泛化表现形式.
设(U,A)是一个不完备信息系统,
$\forall X \subseteq U, B \subseteq A$ ,则X关于特征关系RB的上近似集和下近似集分别定义为根据X关于RB的上、下近似集,可将论域U划分为3个互不相交的区域,分别为正域、边界域及负域,定义为
POS(X)表示一定属于X的对象集,NEG(X)表示一定不属于X的对象集,BND(X)表示不确定是否属于X的对象集. X关于RB的近似精度定义为:
其中|X|表示集合X的基数. X关于RB的粗糙度定义为:
定义3 [14] S=(U,A)是一个多尺度信息系统,其中U={x1,x2,…,xn}为论域,A={a1,a2,…,am}是一个非空有限属性集,且每个属性都是多尺度属性. 假设所有属性都有I个相同的尺度级数,则多尺度信息系统可以表示为(U,{ajk|k=1,2,…,I,j=1,2,…,m}),其中,ajk:U→Vjk,Vjk是属性aj在第k个尺度的值域,对于j=1,2,…,m,k=1,2,…,I-1,存在满射函数gjk,k+1:Vjk→Vjk+1使得ajk+1=gjk,k+1°ajk,即:
称gjk,k+1为粒信息转换函数. 对于k∈{1,2,…,I},记
$ A ^ k =\left \{ a _1^ k , a _2^ k , \cdots , a _ m ^ k \right \}$ ,则一个多尺度信息系统S=(U,A)可以分解为I个信息系统Sk=(U,$ A ^ k $ ),k=1,2,…,I.若S1=(U,A1)是一个不完备信息系统,则称(U,A)=(U,{ajk|k=1,2,…,I,j=1,2,…,m})为不完备多尺度信息系统[30]. 用符号“*”表示未知属性值,即如果ajk(x)=*,就认为x在属性ajk上的值是未知的. 此时不同尺度层次之间的属性值变换为:
其中,j=1,2,…,m; k=1,2,…,I-1; x∈U.
-
本节主要给出混合语义下的不完备多尺度信息系统的定义,并讨论数据填补和特征关系模型的扩展.
-
现有不完备多尺度信息系统的研究通过引入容差关系处理多尺度信息系统中的数据缺失,但只考虑了遗漏型未知属性值,并且认为多尺度信息系统S的不完备是由于S1的不完备,因此对象x在多尺度属性aj下缺失,则aj1(x)=aj2(x)=…=ajI(x)=*,即x在aj的所有尺度下全部缺失. 而在实际应用中,可能存在遗漏型和缺席型未知属性值共存于一个多尺度信息系统,并且对象x只是在多尺度属性的某些尺度下缺失. 因此,针对已有研究的不足,本小节将定义混合语义下的不完备多尺度信息系统.
定义4 多尺度信息系统中的某些属性值未知,并且未知属性值是两种语义的任意解释,则称该信息系统为混合语义下的不完备多尺度信息系统,仍表示为S=(U,A)=(U,{ajk|k=1,2,…,I,j=1,2,…,m}). 符号“*”和“
$ \mathit{\emptyset} $ ”分别表示遗漏和缺席型未知属性值,即若ajk(x)=*或ajk(x)=$ \mathit{\emptyset} $ ,则认为x在属性ajk上的值未知,否则x在属性ajk上的值已知.例1 表 1是一个具有3个尺度和2个属性的混合语义下的不完备多尺度信息系统S=(U,A)=(U,{ajk|k=1,2,3,j=1,2}),其中,U={x1,x2,…,x8},A={a1,a2}. S同时具有遗漏和缺席型未知属性,对象在多尺度属性下存在全部缺失也存在部分缺失,如x2在a1下部分缺失,x5在a2下全部缺失.
-
定理1 (U,{ajk|k=1,2,…,I,j=1,2,…,m})是一个多尺度信息系统,存在粒信息转换函数gjk,k+1:Vjk→Vjk+1,k=1,2,…,I-1,对于∀x,y∈U:
1) ajk+1(x)=gjk,k+1(ajk(x));
2) ajk+1(x)≠ajk+1(y)→ajk(x)≠ajk(y);
3) ajk(x)=ajk(y)→ajk+1(x)=ajk+1(y).
在不完备多尺度信息系统中,对于在多尺度属性aj上部分缺失的对象,如果该对象在aj的粗尺度下未知,而在细尺度下已知,此时根据定理1的1)可以填补粗尺度下的属性值. 因此,下面基于粒信息转换函数给出数据填补方法.
定义5 S=(U,A)=(U,{ajk|k=1,2,…,I,j=1,2,…,m})是混合语义下的不完备多尺度信息系统,gjk,+1:Vjk→Vjk+1是相对S完备的多尺度信息系统的粒信息转换函数. 对于k∈{1,2,…,I},记
$ A ^ k =\left \{ a _1^ k , a _2^ k , \cdots , a _ m ^ k \right \}$ ,Sk=(U,$ A ^ k $ ),数据填补后的Sk记为Sk*,数据填补后的S记为S*,由S1*,S2*,…,SI*组成,其中S1*=S1.对于k∈{1,2,…,I-1},根据gjk,k+1及Sk*对Sk+1进行数据填补得到Sk+1*:∀x∈U,ajk∈
$ A ^ k $ ,若ajk+1(x)=*∨ajk+1(x)=$ \mathit{\emptyset} $ 并且ajk(x)≠*∧ajk(x)≠$ \mathit{\emptyset} $ ,则对ajk+1(x)进行填补有ajk+1(x)=gjk+1(ajk(x)).定理2 设S=(U,A)=(U,{ajk|k=1,2,…,I,j=1,2,…,m})是一个混合语义下的不完备多尺度信息系统,aj∈A,x∈U,对于数据填补后的S*有:
1) 若ajk(x)=*或ajk(x)=
$ \mathit{\emptyset} $ ,则有ajm(x)=*或ajm(x)=$ \mathit{\emptyset} $ ,m∈{1,2,…,k};2) 若ajk(x)≠*且ajk(x)≠
$ \mathit{\emptyset} $ ,则有ajm(x)≠*且ajm(x)≠$ \mathit{\emptyset} $ ,m∈{k,k+1,…,I};3) 若x在aj下部分缺失,即
$\exists $ k∈{1,2,…,I-1}使得ajk(x)=*∨ajk(x)=$ \mathit{\emptyset} $ 而ajk+1(x)≠*∧ajk+1(x)≠$ \mathit{\emptyset} $ ,则有ajm(x)=*∨ajm(x)=$ \mathit{\emptyset} $ ,m∈{1,2,…,k},并且ajn(x)≠*∧ajn(x)≠$ \mathit{\emptyset} $ ,n∈{k+1,k+2,…,I}.例2 已知例1中S对应的完备多尺度信息系统的粒信息转换函数为:g11,2(1)=g11,2(2)=S,g11,2(3)=M,g11,2(4)=g11,2(5)=L; g12,3(S)=Y,g12,3(M)=g12,3(L)=N; g21,2(1)=S,g21,2(2)=g21,2(3)=M,g21,2(4)=g21,2(5)=L; g22,3(S)=N,g22,3(M)=g22,3(L)=Y.
对S进行数据填补:
根据gj1,2及S1*=S1对S2进行数据填补得到S2*:a12(x2)=
$ \mathit{\emptyset} $ 并且a11(x2)=1,则a12(x2)=g11,2(1)=S;根据gj2,3及S2*对S3进行数据填补得到S3*:a13(x2)=
$ \mathit{\emptyset} $ 并且a12(x2)=S,则a13(x2)=g12,3(S)=Y; a13(x6)=*并且a12(x6)=M,则a13(x6)=g12,3(M)=N; a23(x7)=$ \mathit{\emptyset} $ 并且a22(x7)=L,则a23(x7)=g22,3(L)=Y.由S1*,S2*,S3*得到S*,如表 2所示.
-
由于数据填补后可能仍然存在未知值,可以将特征关系引入数据填补后的不完备多尺度信息系统. 针对例2中数据填补后的S*,根据公式2可得x7关于属性子集{a2}在不同尺度下的特征集:K{a21}(x7)=U,K{a22}(x7)={x3,x6,x7,x8},K{a23}(x7)={x2,x4,x6,x7,x8}. 显然不满足多尺度中尺度间的偏序关系K{a21}
$ \subseteq $ K{a22}$ \subseteq $ K{a23}.观察表 2可以发现,在第2尺度下a22(x7)与a22(x1),a22(x2),a22(x4)不相等,在第3尺度下a23(x7)与a23(x3)不相等,由定理1知,在第1尺度下a21(x7)与a21(x1),a21(x2),a21(x3),a21(x4)不相等; 因a22(x5)=
$ \mathit{\emptyset} $ (不可比较),则有x5$ \notin $ [(a22,L)]=K(x7,a22),而x5∈K(x7,a21),为满足尺度间的偏序关系,使得x5$ \notin $ K(x7,a21). 由此得到K{a21}(x7)={x6,x7,x8}.根据上述的分析,需要扩展特征关系模型以满足数据填补后混合语义下的不完备多尺度信息系统尺度间的偏序关系.
定义6 S=(U,A)=(U,{ajk|k=1,2,…,I,j=1,2,…,m})是一个多尺度信息系统,[(ajk,v)]为属性-值对(ajk,v)的块,记:
定义7 S=(U,A)=(U,{ajk|k=1,2,…,I,j=1,2,…,m})是一个混合语义下的不完备多尺度信息系统. 对于数据填补后的S*,Vjk={ajk(x)|x∈U}是属性aj在第k个尺度的值域,对于属性-值对的块[(ajk,v)],有:
1) 若ajk(x)=*,则x∈[(ajk,ajk(z))],其中z∈U-Y,Y={y∈U|(m≠0∧ajm(x)≠ajm(y),m=majk(x))∨(
$\exists $ ajn(x)=$ \mathit{\emptyset} $ ,k<n≤I)};2) 若ajk(x)=
$ \mathit{\emptyset} $ ,则x$ \notin $ [(ajk,v)],其中v∈Vjk.对于∀x∈U,k∈{1,2,…,I},aj∈B
$ \subseteq $ A,K(x,ajk)是x关于属性ajk的广义不可分辨对象集,定义如下:1) 若ajk(x)≠
$ \mathit{\emptyset} $ 且ajk(x)≠*,则2) 若ajk(x)=
$ \mathit{\emptyset} $ 或ajk(x)=*:当ajI(x)=
$ \mathit{\emptyset} $ 或ajI(x)=*时,当ajI(x)≠
$ \mathit{\emptyset} $ 且ajI(x)≠*时,其中
majk(x)表示对象x在属性aj的k尺度后属性值已知的最细尺度,若k尺度后属性值全部未知则majk(x)=0. 记:
KBk(x)是对象x关于属性集B在第k尺度下的特征集.
对于∀x,y∈U,k∈{1,2,…,I},B
$ \subseteq $ A,特征关系$ R _{ B ^ k }$ 是S*在第k尺度下由属性子集B导出的一个广义不可分辨关系:对于x∈U,k∈{1,2,…,I-1},混合语义下的不完备多尺度信息系统S*的粒信息转换函数不是满射函数,仅当ajk(x)≠
$ \mathit{\emptyset} $ 且ajk(x)≠*时,满足ajk+1(x)=gjk,k+1(ajk(x)). 一个混合语义下的不完备多尺度信息系统S*可以分解为I个信息系统Sk*=(U,$ A ^ k $ ),k=1,2,…,I.例3 例2中数据填补后的S*,由定义7可得到x7关于B=A在不同尺度下的特征集,可得KB1(x7)
$ \subseteq $ KB2(x7)$ \subseteq $ KB3(x7).定义8 S1和S2是非空集合U上的2个混合语义下的不完备多尺度信息系统,对于数据填补后的S1*和S2*分别有扩展后的特征关系R1和R2,若对于∀x∈U总有KR1(x)
$ \subseteq $ KR2(x),那么就称U/R1较U/R2更细,或U/R2较U/R1更粗,记为U/R1$ \subseteq $ U/R2.定理3
$\left ( U , \left \{ A ^ k \mid k =1, 2, \cdots , I \right \}\right )$ 是一个混合语义下的不完备多尺度信息系统,对于数据填补后的$S^*, k=1, 2, \cdots I, B \subseteq A$ ,记:如下性质成立:∀x∈U.
1)
$R_{B^k}$ 是自反的,不一定是对称和传递的;2)
$R_{B^k}=\bigcap_{a \in B} R_{a^k}$ ;3) 当
$C \subseteq B \subseteq A$ 时,$R_{A^k} \subseteq R_{B^k} \subseteq R_{C^k}$ ;4) 当
$C \subseteq B \subseteq A$ 时,$K_{A^k}(x) \subseteq K_{B^k}(x) \subseteq K_{C^k}(x)$ ;5)
$R_{B^k} \subseteq R_{B^{k+1}}$ ,其中$k=1, 2, \cdots, I-1$ ;6)
$K_{B^k}(x) \subseteq K_{B^{k+1}}(x)$ , 其中$k=1, 2, \cdots, I-1$ ;7)
$U / R_{B^k} \subseteq U / R_{B^{k+1}}$ , 其中$k=1, 2, \cdots, I-1$ .定义9
$ X \subseteq U, X$ 关于$R_{B^k}$ 的下近似集和上近似集定义为:集合
$B N_{B^k}(X)=\overline{R_{B^k}}(X)-\underline{R_{B^k}}(X)$ 称为X的$R_{B^k}$ 边界域.由定理3和上述上、下近似的定义易得到如下定理:
定理4
$\left(U, \left\{A^k \mid k=1, 2, \cdots, I\right\}\right)$ 是一个混合语义下的不完备多尺度信息系统,对于数据填补后的$ S^*, k=1,2, \cdots I, B \subseteq A$ ,有如下性质成立:$\forall X \subseteq U, Y \subseteq U $ .1)
$\underline{R_{B^k}}(X)=\sim \overline{R_{B^k}}(\sim X)$ ;2)
$\overline{R_{B^k}}(X)=\sim \underline{R_{B^k}}(\sim X)$ ;3)
$R_{B^k}(\varnothing)=\overline{R_{B^k}}(\mathit{\emptyset})=\varnothing$ ;4)
$R_{B^k}(U)=\overline{R_{B^k}}(U)=U$ ;5)
$R_{B^k}(X \cap Y)=R_{B^k}(X) \cap R_{B^k}(Y)$ ;6)
${\overline{R_{B^k}}}(X \cup Y)={\overline{R_{B^k}}}(X) \cup {\overline{R_{B^k}}}(Y)$ ;7)
$X \subseteq Y \Rightarrow \underline{R_{B^k}}(X) \subseteq \underline{R_{B^k}}(Y)$ ;8)
$X \subseteq Y \Rightarrow \overline{R_{B^k}}(X) \subseteq \overline{R_{B^k}}(Y)$ ;9)
$R_{B^k}(X \cup Y) \supseteq R_{B^k}(X) \cup R_{B^k}(Y)$ ;10)
${\overline{R_{B^k}}}(X \cap Y) \subseteq \overline{R_{B^k}}(X) \cap \overline{R_{B^k}}(Y)$ ;11)
$R_{B^k}(X) \subseteq X \subseteq \overline{R_{B^k}}(X)$ ;12)
$\overline{R_{B^{k+1}}}(X) \subseteq R_{B^k}(X), k=1, 2, \cdots, I-1$ ;13)
$\overline{R_{B^k}}(X) \subseteq \overline{R_{B^{k+1}}}(X), k=1, 2, \cdots, I-1$ .X关于
$R_{B^k}$ 的粗糙度定义为:可得到不同的尺度下X的近似精度与粗糙度的关系.
定理5
$\left(U, \left\{A^k \mid k=1, 2, \cdots, I\right\}\right)$ 是一个混合语义下的不完备多尺度信息系统,对于数据填补后的$S^*, k=1, 2, \cdots, I-1, B \subseteq A$ ,则$\forall X \subseteq U$ .1)
$\alpha_{B^{k+1}}(X) \leqslant \alpha_{R_{B^k}}(X)$ ;2)
$\rho_{B^k}(X) \leqslant \rho_{R^{k+1}}(X)$ .定理5表明,尺度越小(细),集合X的近似精度越高而粗糙度越小.
2.1. 混合语义下的不完备多尺度信息系统
2.2. 数据填补
2.3. 特征关系的模型扩展
-
在第2节的工作基础之上,本节将给出混合语义下不完备多尺度信息系统的序贯三支决策模型,并基于此模型在混合语义下的不完备多尺度决策系统中选择不确定性最小的尺度作为最优尺度.
-
定义10
$S=(U, A)=\left(U, \left\{a_j^k \mid k=1, 2, \cdots I, j=1, 2, \cdots, m\right\}\right)$ 是一个混合语义下的不完备多尺度信息系统,记$A^k=\left\{a_1^k, a_2^k, \cdots, a_m^k\right\}$ . 对于数据填补后的$S^*, X \subseteq U$ 关于$A^k$ 的三支决策(接受、拒绝和不确定)分别定义为$A C P\left(A^k, X\right), R E J\left(A^k, X\right)$ 和$U N C\left(A^k, X\right)$ . 其中$A C P\left(A^k, X\right)$ 表示U中在特征关系$R_{A^k}$ 下一定属于X的对象集,$R E J\left(A^k, X\right)$ 表示U中在特征关系$R_{A^k}$ 下一定不属于X的对象集,$U N C\left(A^k, X\right)$ 表示U中在特征关系$R_{A^k}$ 下不确定是否属于X的对象集.定理6 设
$S=(U, A)=\left(U, \left\{a_j^k \mid k=1, 2, \cdots I, j=1, 2, \cdots, m\right\}\right)$ 是一个混合语义下的不完备多尺度信息系统. 对于数据填补后的S*,k=1,2,…,I-1,根据X关于$ A ^ k $ 的三支决策,可得到X关于$ A ^{ k +1}$ 的三支决策.1) 接受:
$A C P\left(A^{k+1}, X\right)=\left\{x \in A C P\left(A^k, X\right) \mid K_{A^{k+1}}(x) \subseteq X\right\} $ ;2) 拒绝:
$ R E J\left(A^{k+1}, X\right)=\left\{x \in R E J\left(A^k, X\right) \mid K_{A^{k+1}}(x) \cap X=\mathit{\emptyset}\right\}$ ;3) 不确定:
证 由定理3知
$K_{B^k}(x) \subseteq K_{B^{k+1}}(x)$ :1) 对于
$\forall x \in A C P\left(A^k, X\right)$ , 始终满足$K_{A^k}(x) \subseteq X$ , 于是有$K_{A^{k+1}}(x) \cap X \neq \mathit{\emptyset}$ . 因此$x \notin$ $R E J\left(A^{k+1}, X\right)$ ; 若$K_{A^{k+1}}(x) \subseteq X$ 则有$x \in A C P\left(A^{k+1}, X\right)$ .2) 对于
$\forall x \in R E J\left(A^k, X\right)$ , 始终满足$K_{A^k}(x) \cap X=\mathit{\emptyset}$ , 于是有$K_{A^{k+1}}(x) \nsubseteq X$ . 因此$\notin$ $A C P\left(A^{k+1}, X\right)$ ; 若$K_{A^{k+1}}(x) \cap X=\mathit{\emptyset}$ 则有$x \in R E J\left(A^{k+1}, X\right)$ .3) 对于
$\forall x \in U N C\left(A^k, X\right)$ , 始终满足$K_{A^k}(x) \nsubseteq X$ 并且$K_{A^k}(x) \cap X \neq \mathit{\emptyset}$ , 于是有$K_{A^{k+1}}(x) \nsubseteq$ $X$ 且$K_{A^{k+1}}(x) \cap X \neq \mathit{\emptyset}$ . 因此$x \notin A C P\left(A^{k+1}, X\right)$ 且$x \notin R E J\left(A^{k+1}, X\right)$ .由以上得到1)2)的证明;
对于
$\forall x \in A C P\left(A^k, X\right)$ 始终有$K_{A^k}(x) \subseteq X$ , 因此$K_{A^{k+1}}(x) \cap X \neq \mathit{\emptyset}$ , 若$K_{A^{k+1}}(x) \nsubseteq X$ 则有$x \in U N C\left(A^{k+1}, X\right)$ ; 对于$\forall x \in R E J\left(A^k, X\right)$ 始终有$K_{A^k}(x) \cap X=\mathit{\emptyset}$ , 因此$K_{A^{k+1}}(x) \nsubseteq X$ , 若$K_{A^{k+1}}(x) \cap X \neq \mathit{\emptyset}$ 则有$x \in U N C\left(A^{k+1}, X\right)$ ; 对于$\forall x \in U N C\left(A^k, X\right)$ 始终有$K_{A^k}(x) \nsubseteq X$ 并且$K_{A^k}(x) \cap X \neq \mathit{\emptyset}$ , 因此$K_{A^{k+1}}(x) \nsubseteq X$ 并且$K_{A^{k+1}}(x) \cap X \neq \mathit{\emptyset}$ , 即$x \in U N C\left(A^{k+1}, X\right)$ . 由此得到3) 的证明.由定理6知三支决策
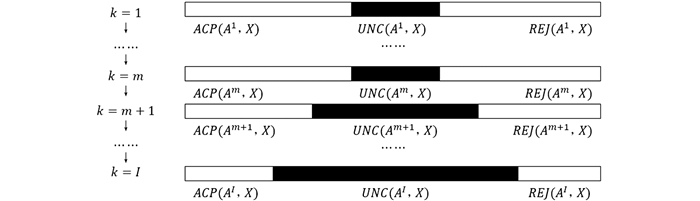
$A C P\left(A^k, X\right)$ ,$R E J\left(A^k, X\right)$ 和$U N C\left(A^k, X\right)$ 从k尺度到k+1尺度是单调变化的,变化过程如定理7所示.定理7 设
$S=(U, A)=\left(U, \left\{a_j^k \mid k=1, 2, \cdots I, j=1, 2, \cdots, m\right\}\right)$ 是一个混合语义下的不完备多尺度信息系统. 对于数据填补后的$S^*, k=1, 2, \cdots, I-1$ ,有:1)
$A C P\left(A^k, X\right) \supseteq A C P\left(A^{k+1}, X\right)$ ;2)
$R E J\left(A^k, X\right) \supseteq R E J\left(A^{k+1}, X\right)$ ;3)
$U N C\left(A^k, X\right) \subseteq U N C\left(A^{k+1}, X\right)$ .混合语义下的不完备多尺度信息系统的序贯三支决策模型是在尺度增加(粗化)的过程中对
$A C P\left(A^k, X\right)$ 和$R E J\left(A^k, X\right)$ 的进一步决策,使得属于$A C P\left(A^k, X\right)$ 或$R E J\left(A^k, X\right)$ 的对象可能会增加到$U N C\left(A^{k+1}, X\right)$ 中. 三支决策从最细尺度到最粗尺度的整个动态过程如图 1所示. -
在不完备多尺度决策系统中,尺度越细的决策系统的不确定性越小而在尺度越粗的决策系统中获取的规则越简单[30]. 本节将利用序贯三支决策的不确定(UNC)量化决策系统的不确定性,选择不确定性最小且尽可能粗的尺度作为最优尺度.
定义11 一个混合语义下的不完备多尺度决策系统可以表示为:
其中
$(U, A)=\left(U, \left\{a_j^k \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\}\right)$ 是一个混合语义下的不完备多尺度信息系统.$A$ 为条件属性集,$d \notin A$ 为一个单尺度属性, 称为决策属性,$d: U \rightarrow V_d, V_d$ 为决策属性$d$ 的值域.定义12 d(x)为x在决策属性d下的属性值,关于决策属性d的等价关系定义为:
包含x的决策类
$[x]_{R_d}=\left\{y \in U \mid(x, y) \in R_d\right\}$ . 由决策属性d导出的划分$U / R_d=\left\{[x]_{R_d} \mid x \in U\right\}$ .定理8 设
$S=\left(U, \left\{a_j^k \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\} \cup\{d\}\right)$ 是一个混合语义下的不完备多尺度决策系统,记$A^k=\left\{a_1^k, a_2^k, \cdots, a_m^k\right\}$ ,对于数据填补后的$S^*, U / R_d=\left\{D_1, D_2, \cdots, D_p\right\}, k=1, 2, \cdots$ ,$I-1$ ,根据$D_i \in U / R_d$ 关于$A^k$ 的三支决策,可得到$D_i$ 关于$A^{k+1}$ 的三支决策.1) 接受:
$A C P\left(A^{k+1}, D_i\right)=\left\{x \in A C P\left(A^k, D_i\right) \mid K_{A^{k+1}}(x) \subseteq D_i\right\}$ ;2) 拒绝:
$ {REJ}\left(A^{k+1}, D_i\right)=\left\{x \in R E J\left(A^k, D_i\right) \mid K_{A^{k+1}}(x) \cap D_i=\mathit{\emptyset}\right\}$ ;3) 不确定:
显然,随着尺度增加,
$U N C\left(A^k, D_i\right)$ 单调不减. 定理6与定理8的不同之处在于三支决策的目标对象不同. 具体来说,前者利用不同尺度下特征关系导出的覆盖对目标概念进行序贯三支决策,而后者则是决策属性导出的划分U/Rd的序贯三支决策.定义13
$ S=(U, A \cup\{d\})=\left(U, \left\{a_j^k \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\} \cup\{d\}\right)$ 是一个混合语义下的不完备多尺度决策系统,记$A^k=\left\{a_1^k, a_2^k, \cdots, a_m^k\right\}$ ,对于数据填补后的$S^*, x \in U$ ,记:$\partial_{A^k}(x)$ 是x关于属性集A在第k尺度下的广义决策值.定理9 设
$S=\left(U, \left\{a_j^k \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\} \cup\{d\}\right)$ 是一个混合语义下的不完备多尺度决策系统. 对于数据填补后的$S^*, U / R_d=\left\{D_1, D_2, \cdots, D_p\right\} . \forall D_i \in U / R_d$ ,若$x \in U N C\left(A^k, D_i\right)$ ,则有$\left|\partial_{A^k}(x)\right|>1$ .证
$\forall x \in U N C\left(A^k, D_i\right)$ 始终满足$K_{A^k}(x) \nsubseteq D_i$ 并且$K_{A^k}(x) \cap D_i \neq \mathit{\emptyset}$ ,于是存在$x_1, x_2 \in$ $K_{A^k}(x)$ 和$x_3 \in D_i$ 满足$d\left(x_3\right)=d\left(x_1\right)$ 而$d\left(x_3\right) \neq d\left(x_1\right)$ , 因此$d\left(x_2\right) \neq d\left(x_1\right)$ , 也就是$\left|\partial_{A^k}(x)\right|=$ $\left|\left\{d(y) \mid y \in K_{A^k}(x)\right\}\right|>1$ .定义14 设
$S=\left(U, \left\{a_j^k \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\} \cup\{d\}\right)$ 是一个混合语义下的不完备多尺度决策系统. 对于数据填补后的S*,记$A^k=\left\{a_1^k, a_2^k, \cdots, a_m^k\right\}, U / R_d=\left\{D_1, D_2, \cdots, D_p\right\}$ . 若$\exists $ $D_i \in U / R_d$ 使得$U N C\left(A^k, D_i\right)$ UNC($A^{k+1}$ ,$D_i$ )并且∀$D_i \in U / R_d$ ,∀l<k满足$U N C\left(A^k, D_i\right)=$ $U N C\left(A^l, D_i\right)$ ,那么就称k为基于不确定性的最优尺度.由定理7可以得到随着尺度的增加(粗化)
$U N C\left(A^k, D_i\right)$ 单调不减. 通过定义14知,当k为最优尺度时,存在$D_i \in U / R_d$ 使得$U N C\left(A^k, D_i\right)$ 随着尺度增加而增大. 因此,最优尺度是使得$U N C\left(A^k, D_i\right)$ 最小的所有尺度中最粗的尺度. 从不确定性最小即为最优的角度来说,在最优尺度进行决策是有效的.在尺度细化的过程中,文献[29]选择不确定性不再改变的尺度作为最优尺度. 然而,当增加的尺度是冗余的时,不确定性很容易保持不变[20],此时选择的最优尺度的不确定性不是最小. 定义14给出的最优尺度选择方法弥补了此缺陷,得到的最优尺度的不确定性总是最小. 对于一个混合语义下的不完备多尺度决策系统,最优尺度选择步骤如算法1所示.
算法1 混合语义下的不完备多尺度决策系统最优尺度选择
输入:数据填补后混合语义下的不完备多尺度决策系统S*=(U,A∪{d})=(U,{ajk|k=1,2,…,I,j=1,2,…,m}∪{d});
输出:最优尺度k.
1) 计算决策属性的划分:U/Rd={D1,D2,…,Dp};
2) for each i∈{1,2,…,p}
3) 计算
$A C P\left(A^1, D_i\right), R E J\left(A^1, D_i\right), U N C\left(A^1, D_i\right)$ ;4) end for
5)
$k=1$ ;6) while
$k \leqslant I-1$ 7)
$end\_condition =0$ ;8) for each
$i \in\{1, 2, \cdots, p\}$ 9) initialize
$M=\varnothing$ ;10) for each
$x \in A C P\left(A^k, D_i\right) \cup R E J\left(A^k, D_i\right)$ 11) if
$K_{A^{k+1}}(x) \nsubseteq D_i$ and$K_{A^{k+1}}(x) \cap D_i \neq \mathit{\emptyset}$ then12)
$M \leftarrow M \cup\{x\}$ ;13) end for
14) if
$M \neq \varnothing$ then15)
$U N C\left(A^{k+1}, D_i\right)=U N C\left(A^k, D_i\right) \cup M$ ;16)
$end\_condition =1$ ;17) break;
18) else
19)
$U N C\left(A^{k+1}, D_i\right)=U N C\left(A^k, D_i\right)$ ;20) end for
21) if
$end\_condition =1$ then22) break;
23)
$k=k+1$ ;24) end while
25) return
$k$ .算法1首先计算了由决策属性d导出的划分U/Rd,时间复杂度为O(n2). 2-4在第1尺度下计算所有决策类的三支决策,时间复杂度是O(n|p|),其中每次计算涉及特征集的计算,而每个特征集的计算需要时间复杂度为O(nmI),所以时间复杂度为O(n2mI|p|). 接着根据序贯三支决策(UNC)计算基于不确定性的最优尺度,有3层循环嵌套,同样内循环涉及特征集的计算,所以在最坏的情况下时间复杂度为O(n2I2m|p|). 所以总的时间复杂度为O(n2I2m|p|).
例3 表 3是一个完成数据补充后的不完备多尺度决策系统S*=(U,A={ajk|k=1,2,…,5,j=1,2,3}∪{d}),其中U={x1,x2,…,x10},关于决策属性的论域划分U/Rd={D1,D2},D1={x1,x2,x3,x6,x7},D2={x4,x5,x8,x9,x10}.
根据算法1,从S*中选择最优尺度的过程如下:
1) 在第1尺度下, 关于
$A^1=\left\{a_1^1, a_2^1, a_3^1\right\}$ 有$K_{A^1}\left(x_1\right)=\left\{x_1\right\}, K_{A^1}\left(x_2\right)=\left\{x_2\right\}, K_{A^1}\left(x_3\right)=\left\{x_3\right\}$ ,$K_{A^1}\left(x_4\right)=\left\{x_4, x_6\right\}, K_{A^1}\left(x_5\right)=\left\{x_5\right\}, K_{A^1}\left(x_6\right)=\left\{x_4, x_6\right\}, K_{A^1}\left(x_7\right)=\left\{x_7\right\}, K_{A^1}\left(x_8\right)=\left\{x_8\right\}$ ,$K_{A^1}\left(x_9\right)=\left\{x_9\right\}, K_{A^1}\left(x_{10}\right)=\left\{x_{10}\right\}$ . 显然,$U N C\left(A^1, D_1\right)=\overline{R_{A^1}}\left(D_1\right)-\underline{R_{A^1}}\left(D_1\right)=\left\{x_4, x_6\right\}, U N C\left(A^1\right.$ ,$\left.D_2\right)=\left\{x_4, x_6\right\}$ ;2) 在第2尺度下, 关于
$A^2=\left\{a_1^2, a_2^2, a_3^2\right\}$ 有$K_{A^2}\left(x_1\right)=\left\{x_1\right\}, K_{A^2}\left(x_2\right)=\left\{x_2\right\}, K_{A^2}\left(x_3\right)=\left\{x_3\right\}$ ,$K_{A^2}\left(x_5\right)=\left\{x_5\right\}, K_{A^2}\left(x_7\right)=\left\{x_7\right\}, K_{A^2}\left(x_8\right)=\left\{x_8\right\}, K_{A^2}\left(x_9\right)=\left\{x_9, x_{10}\right\}, K_{A^2}\left(x_{10}\right)=\left\{x_9, x_{10}\right\}$ . 由定理8可得到$U N C\left(A^2, D_1\right)=U N C\left(A^1, D_1\right) \cup \mathit{\emptyset}=\left\{x_4, x_6\right\}, U N C\left(A^2, D_2\right)=\left\{x_4, x_6\right\}$ ;3) 在第3尺度下, 关于
$A^3=\left\{a_1^3, a_2^3, a_3^3\right\}$ , 同理可得$U N C\left(A^3, D_1\right)=U N C\left(A^3, D_2\right)=\left\{x_4, x_6\right\}$ ;4) 在第4尺度下, 关于
$A^4=\left\{a_1^4, a_2^4, a_3^4\right\}$ , 有$U N C\left(A^4, D_1\right)=U N C\left(A^4, D_2\right)=\left\{x_4, x_5, x_6, x_7\right\}$ . 因此有$U N C\left(A^3, D_i\right)=U N C\left(A^2, D_i\right)=U N C\left(A^1, D_i\right)(i=1, 2)$ 而$U N C\left(A^3, D_i\right) \subset U N C\left(A^4\right.$ ,$\left.D_i\right)(i=1, 2)$ . 最后选择第3尺度作为$S^*$ 的最优尺度.
3.1. 混合语义下的不完备多尺度信息系统的序贯三支决策模型
3.2. 基于序贯三支决策模型的最优尺度选择算法
-
为了验证在混合语义下的不完备多尺度决策系统中的数据填补和模型扩展以及最优尺度选择算法的可行性与有效性,本研究从UCI数据库中选出5个数据集进行数值模拟,分别为Seeds,Glass Identification,Wholesale Customers,Balance Scale,Car Evaluation,数据集的详细信息如表 4所示.
为满足实验要求,本研究借鉴文献[29]的方法将表 4中的数据集重新构造为多尺度决策系统. 表 5列出了经过预处理后的数据集信息. 在多尺度决策系统中随机丢失一定百分比的条件属性值,从而得到不同缺失率的不完备多尺度决策系统. 若属性值的缺失使得所在属性的值域减小时,将该未知属性值解释为缺席型,否则解释为遗漏型. 最后得到混合语义下的不完备多尺度决策系统.
为验证2.2和2.3小节中的数据填补和模型扩展的有效性,将文献[34]定义的广义不可分辨关系的分类精度μR作为评价标准. 具体公式定义为:
其中,在完备信息系统S1=(U,A)中,E为U上的等价关系,[x]E表示x的等价类; 在S1中引入一定百分比的缺失值后有不完备信息系统S2=(U′,A),R为U′上广义不可分辨关系(特征关系),R(x)表示x的广义不可分辨对象集(特征集). 当不完备信息系统S2导出的覆盖U′/R越接近完备信息系统S1导出的划分U/E,S2的分类精度越高; 当S2导出的覆盖完全还原S1的划分,则取最大值1.
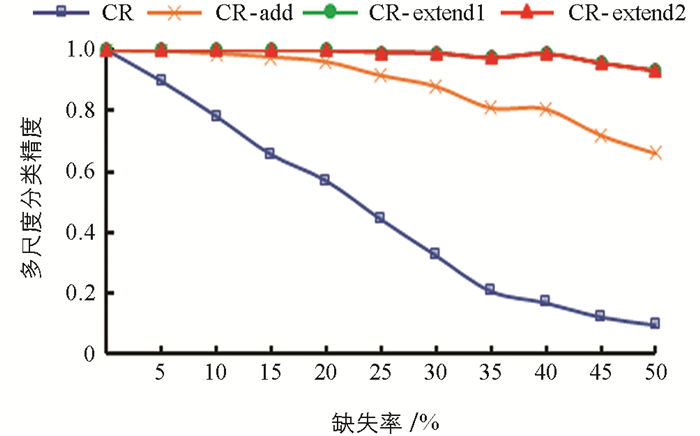
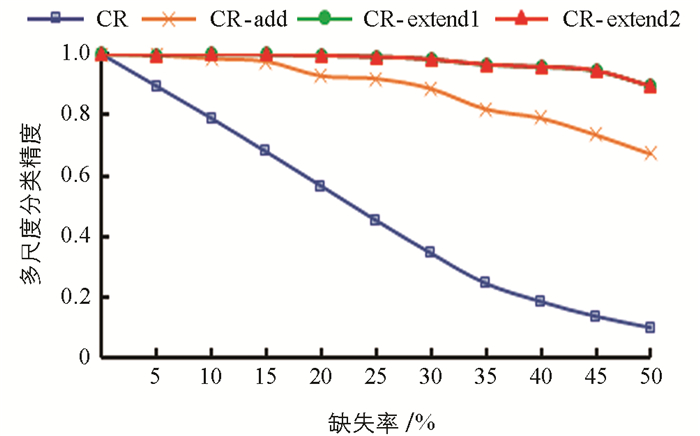
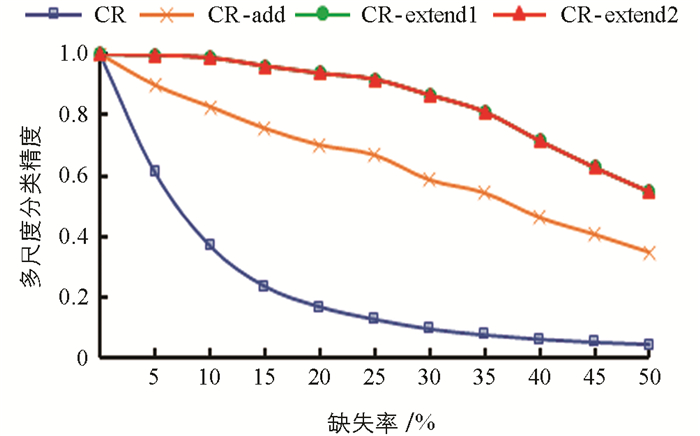
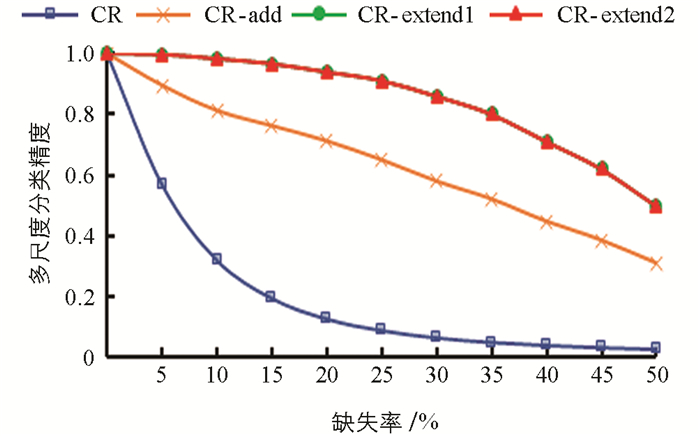
表 6~表 10分别是5个数据集在35%缺失率下4种阶段的单尺度分类精度,图 2~图 6为5个数据集在0~50%的缺失率下4种阶段的多尺度分类精度,多尺度分类精度即为所有单尺度分类精度的平均值. 其中,CR表示将特征关系直接引入不完备多尺度决策系统; CR-add表示在引入特征关系的基础上对系统进行数据填补; CR-extend1指在CR-add的基础上针对特征关系不满足偏序关系的第一次模型扩展,即通过粗尺度下已知属性值的不相等预判细尺度下存在未知属性值的两个对象是不相等的; CR-extend2则是在CR-extend1的基础上针对缺席型未知属性值“
$ \mathit{\emptyset} $ ”的不可比较导致不满足偏序关系而进行的第二次模型扩展.具体地,针对Seeds数据集,实验结果如表 6和图 2所示. 表 6中第1尺度下数据得不到填补,因此CR-add的分类精度等于CR的分类精度,其余尺度下的分类精度CR-add大于CR; 在第6尺度下,CR-extend1与CR-add的分类精度相同,其余尺度下CR-extend1大于等于CR-add的分类精度; CR-extend2与CR-extend1的分类精度保持不变,对于Glass Identification数据集,CR-extend2相对于CR-extend1的分类精度在尺度1下增高0.005,总体而言变化不大. 针对图 2中的多尺度分类精度,在0~50%的缺失率下,CR-add,CR-extend1相对于前一阶段都得到了或多或少的提升,CR-extend2和CR-extend1持平,即因缺席型未知属性值“
$ \mathit{\emptyset} $ ”的不可比较,未保持偏序关系的模型扩展对分类精度影响不大. 表 7~表 10以及图 3~图 6分别是其他4个数据集的分类精度结果,同样符合Seeds数据集的分析结论. 因此进行数据填补和模型扩展后(CR-extend2)的分类精度相对于直接引入特征关系(CR)的分类精度更高,有利于后续知识获取达到更高的确定性,验证了其有效性.表 11是5个数据集在5%的缺失率下,经数据填补和模型扩展后算法1的最优尺度实验结果. 其中OLS是算法1得到的基于不确定性的最优尺度. HC'OLS表示文献[29]中定义的最优尺度,其标准是随着尺度变细,不确定性不变的尺度即为最优尺度. 从实验结果可以看出,随着尺度级数的变小(细化),不确定性存在保持不变后减小的情况. 对于Seeds,Balance Scale和Car Evaluation数据集,HC'OLS的不确定性不是最小的,而本研究提出的方法可得到不确定性最小的最优尺度.
-
本研究分析发现目前研究中对不完备多尺度信息系统的定义存在局限,因此定义混合语义下的不完备多尺度信息系统,即未知属性值可以是任意的语义解释(遗漏和缺席型未知属性值)并且对象在多尺度属性下缺失时不局限于全部缺失. 引入特征关系以处理此类更为一般的不完备多尺度信息系统,为保持尺度间偏序关系对混合语义下的不完备多尺度信息系统进行数据填补和特征关系的模型扩展,同时给出在不同尺度下信息粒度的表示及其相互关系,定义了集合的上、下近似集概念,并讨论了它们的性质. 基于上述工作,在混合语义下的不完备多尺度决策系统中建立序贯三支决策模型,基于该模型选择不确定性最小的尺度作为最优尺度. 本研究所定义的最优尺度与已有的方法略有不同,选择不确定性最小的尺度作为最优尺度是直观且容易理解的,并且无需从一致和不一致的不完备多尺度决策系统两个角度分别讨论最优尺度. 通过实验证明,经数据填补和模型扩展后,不完备多尺度决策系统的分类精度得到提升,并且选择的最优尺度是所有尺度中不确定性最小的.